方式一:yum命令安装
1 | yum -y install lrzsz |
方式二:手动安装
1 | # 下载lrzsz安装包 |
使用
1 | # 下载 |
1 | yum -y install lrzsz |
1 | # 下载lrzsz安装包 |
1 | # 下载 |
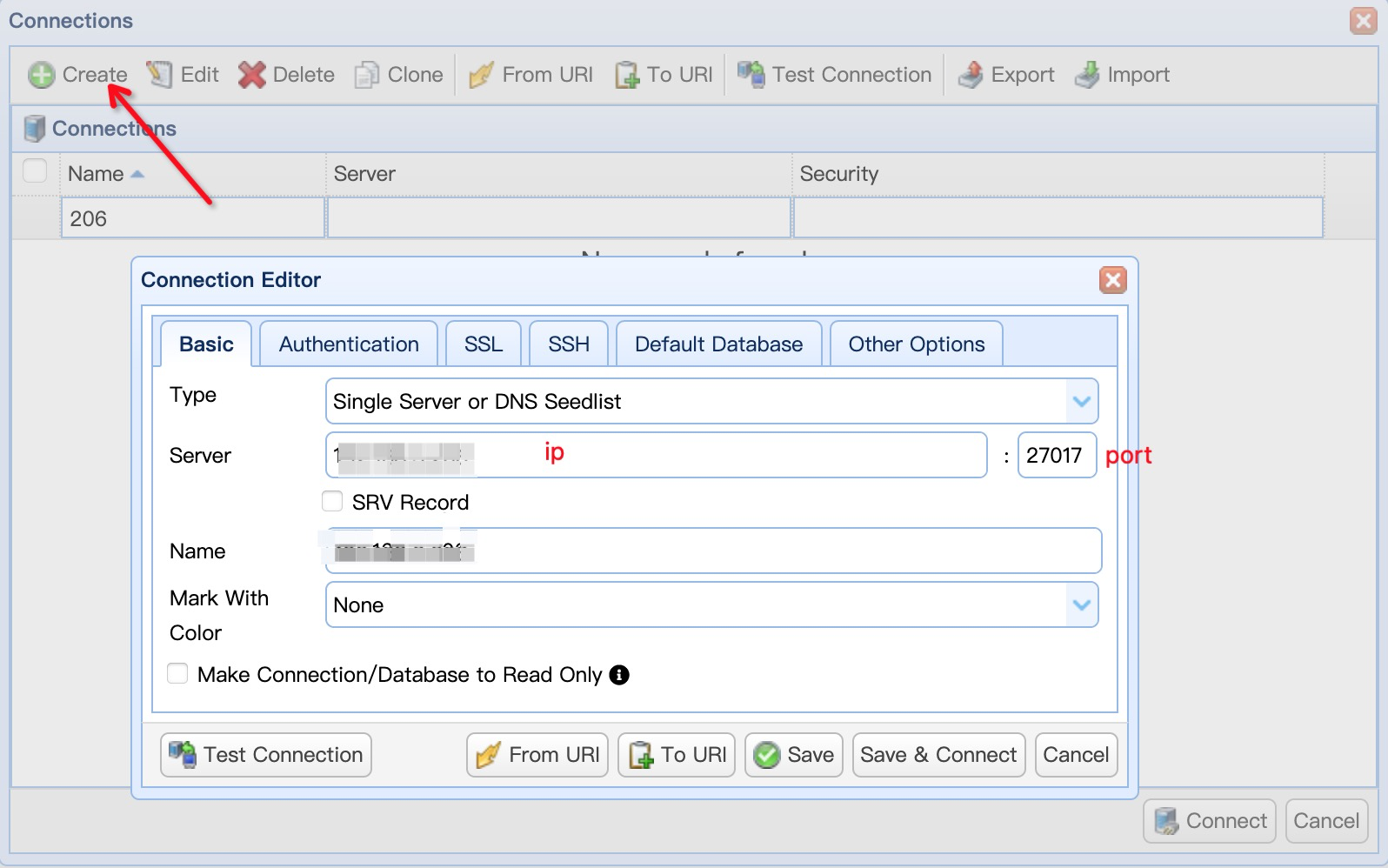
客户端工具 NoSQLBooster for MongoDB
下载地址:https://nosqlbooster.com/downloads
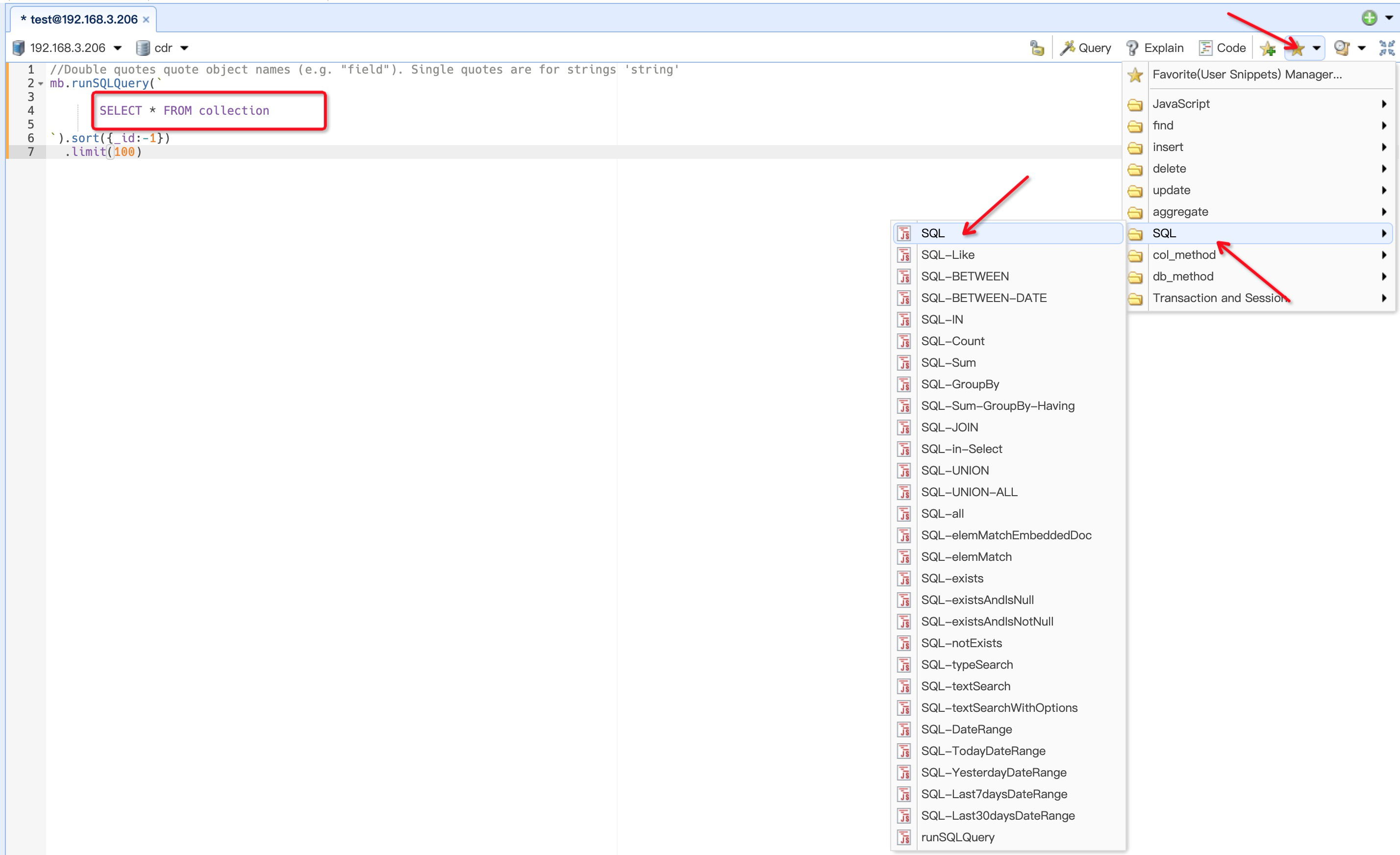
可以打开SQL脚本执行窗口,如下图在runSQLQuery里可以写sql进行查询操作
1 | db.visitInfo.find({ |
1 | db.visitInfo.updateMany({ |
1 | db.visitInfo.remove({ |