这是最近读到的讲关于 JDBC 的超时问题最透彻的文章,原文是http://www.cubrid.org/blog/understanding-jdbc-internals-and-timeout-configuration ,网上现有的翻译感觉磕磕绊绊的,很多上下文信息丢失了,这里用我的理解重新翻译一下。
应用程序中配置恰当的 JDBC 超时时间能减少服务失败的时间,这篇文章我们将讨论不同种类的超时和推荐的配置。
Web 应用服务器在 DDoS 攻击后变得无响应
(这是一个真实案例的发生过程复述)
在 DDoS 攻击之后,整个服务都不能正常工作了,因为第四层交换机不能工作,网络连接断开了,这也导致 WAS (可以将 WAS 理解为作者公司的应用程序)不能正常工作。攻击发生后不久,安全团队拦截了所有 DDoS 攻击,然后网络恢复正常,但 WAS 还是不能工作。
通过分析系统的 dump 日志发现,业务系统停在了 JDBC API 的调用上。20分钟后系统仍处于等待状态无法响应,大概过了30分钟,系统突然发生异常,然后服务恢复正常。
为什么已经将查询超时时间设置成3秒, WAS 却等待了30分钟?为什么30分钟后 WAS 又开始工作了?
如果理解了 JDBC 的超时机制就能找到答案。
为什么我们需要知道 JDBC 驱动
当有性能问题或系统级错误时,WAS 和数据库是我们关注的两个重要层面。在我公司 WAS 和数据库通常由不同的部门负责,因此每个部门聚焦在各自负责的领域来设法弄清楚状况。此时 WAS 和数据库之间的部分会因为得不到足够的关注而产生盲区。对于 Java 应用,这个盲区在数据库连接池和 JDBC 之间,本文我们将重点讨论 JDBC。
什么是 JDBC 驱动
JDBC 是 Java 应用程序中用于访问数据库的一套标准 API,Sun 公司定义了4种类型的 JDBC 驱动。我公司主要用的是第4种,该类型驱动由纯 Java 语言编写,在 Java 应用中通过 socket 与数据库通信。
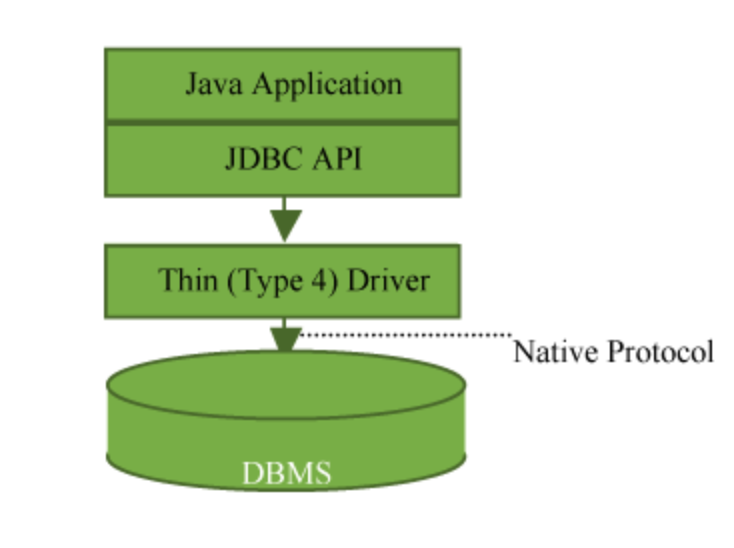
图1: 类型4驱动
类型4驱动是通过 socket 来处理字节流的,它的基本操作和 HttpClient 这种网络操作类库相同。同其他网络类库一样,也会在发生超时的时候占用大量的 CPU 资源从而失去响应。如果你之前用过 HttpClient ,肯定遇到过因为没有设置超时导致的错误。如果 socket 超时设置不合适,类型4驱动也可能有同样的错误(连接被阻塞)。
下面让我们了解如何配置 JDBC 驱动的 socket 超时,以及设置时需考虑哪些问题。
WAS 与数据库间的设置超时的层次
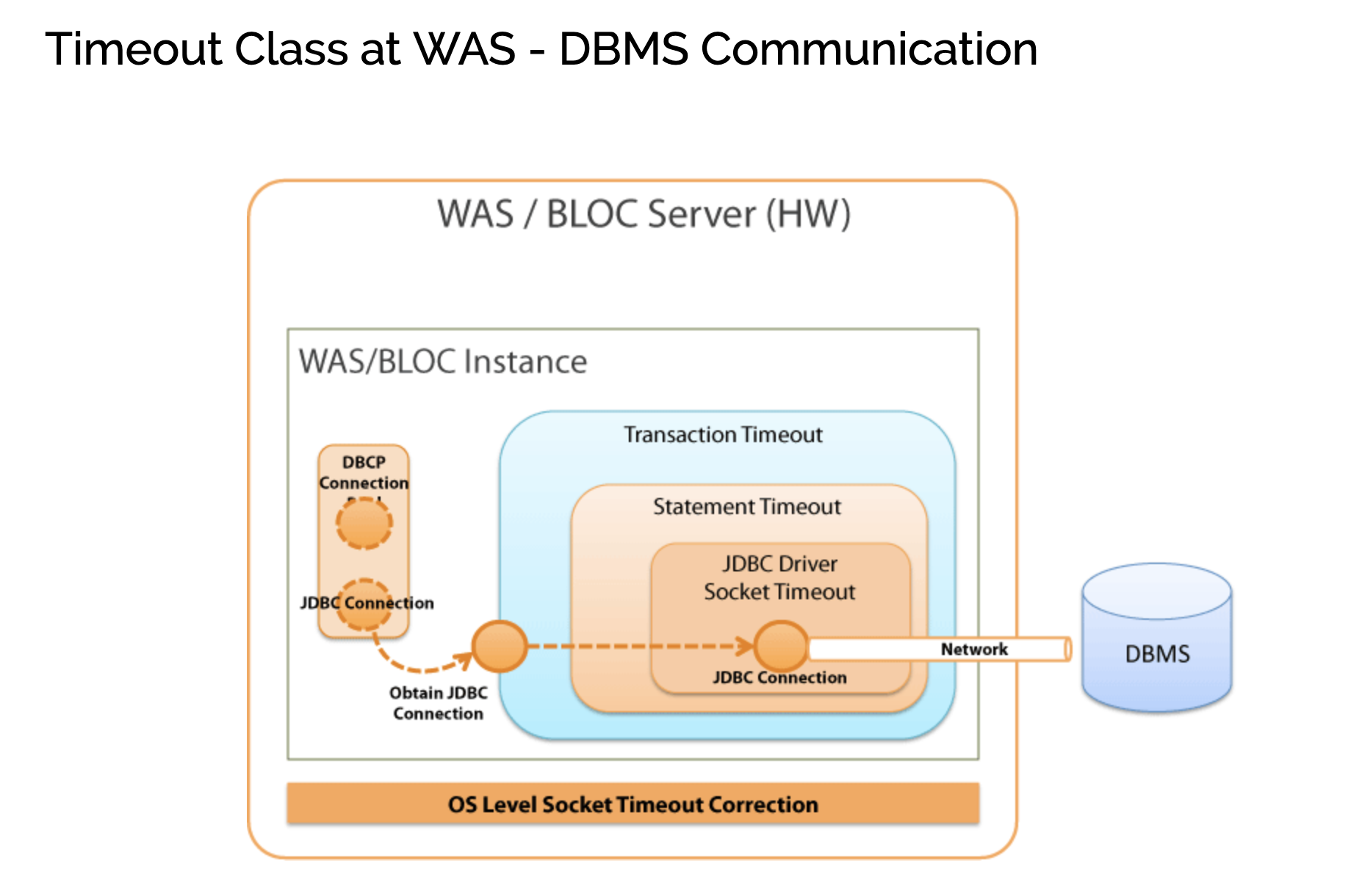
图2: 超时的层次
图2展示了简化的 WAS 和数据库通信时的超时层次。
更上层的超时依赖于下层的超时,只有当较低层的超时机制正常工作,上层的超时才会正常。如果 JDBC 驱动程序的 socket 超时工作不正常,那么更上层的超时比如 Statement 超时和事务超时都不会正常工作。
我们收到很多评论说:
即使配置了 Statement 超时,应用程序还是不能从故障中恢复,因为 Statement 超时在网络故障时不起作用。
Statement 超时在网络故障时不起作用。它只能做到:限制一次Statement 执行的时间,处理超时以防网络故障必须由 JDBC 驱动来做。
JDBC 驱动的 socket 超时还会受操作系统的 socket 超时配置的影响。这解释了为什么案例中的 JDBC 连接在网络故障后阻塞了30分钟才恢复,即使没配置 JDBC 驱动的 socket 超时。
DBCP 连接池位于图2的左边。你会发现各种层面的超时与 DBCP 是分开的。DBCP 负责数据库连接(即本文中说到的Connection)的创建和管理,并不涉及超时的处理。当在 DBCP 中创建了一个数据库连接或发送了一条查询校验的 sql 语句用于检查连接有效性时,socket 超时会影响这些过程的处理,但并不直接影响应用程序。
然而在应用程序中调用 DBCP 的 getConnection() 方法时,你能指定应用程序获取数据库连接的超时时间,但这和 JDBC 的连接超时无关。
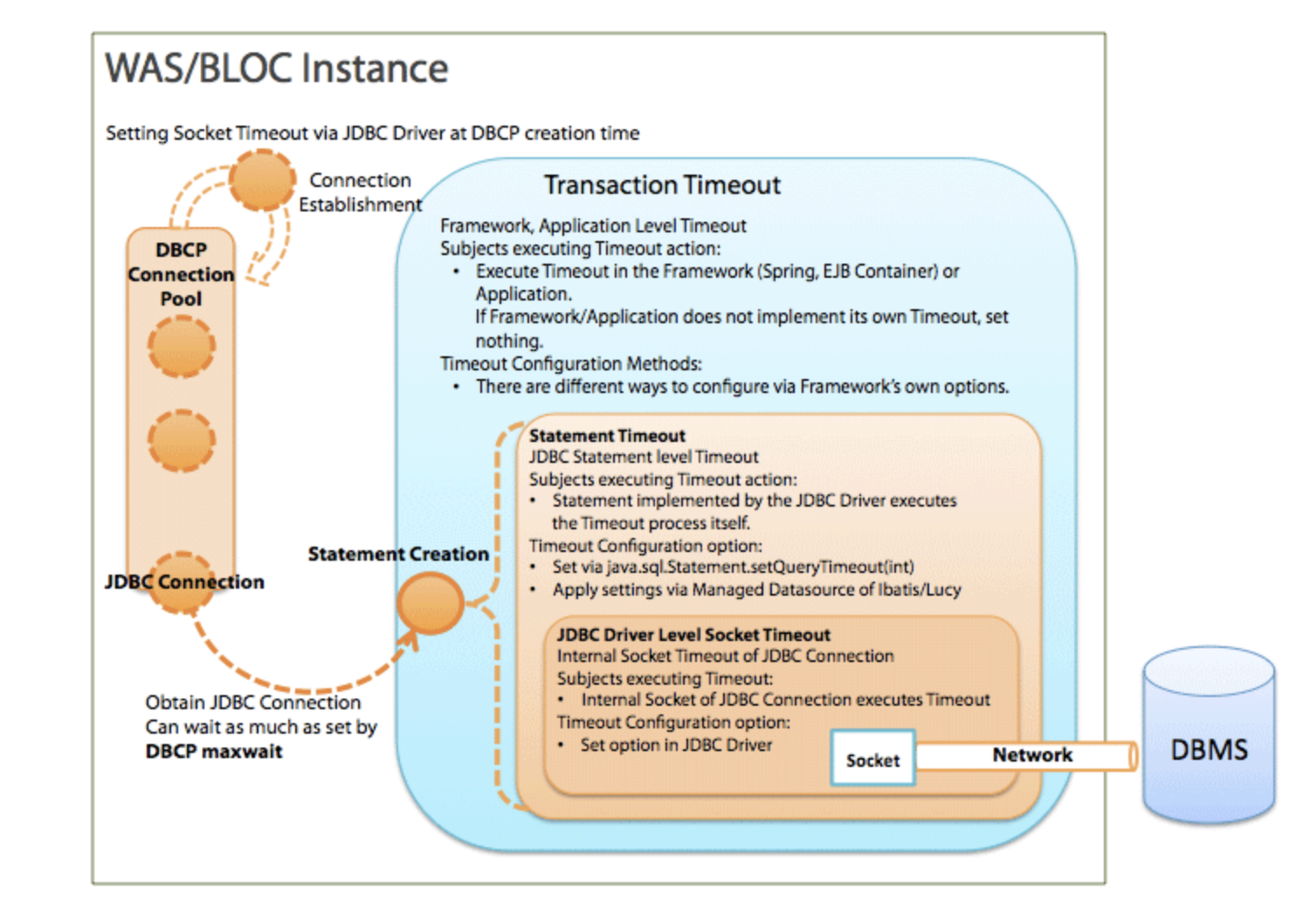
图3: 每一层级的超时
什么是事务超时
事务超时是在框架(Spring、EJB容器)或应用程序层面上才有效的超时。
事务超时可能是个不常见的概念。简单讲,事务超时等于** Statement 超时 * N(需要执行的 Statement 的数量) + 其它(垃圾回收等其他时间)**。事务超时被用来限制执行一个事务之内所有 Statement 执行的总时长。
比如,假设执行一次 Statement 执行需0.1秒,那执行几次 Statement
并不是什么问题,但如果是执行十万次则需要一万秒(大约7个小时),这就可以用上事务超时了。
EJB 的声明式事务管理 (容器管理事务) 就是一种典型的使用场景,但声明式事务管理只是定义了相应的规范,容器内事务的处理过程和具体实现由容器的开发者负责。我们公司并没有用 EJB,用的是最常见的 Spring 框架,所以事务超时的配置也由 Spring 来管理。在 Spring 中,事务超时可以在 XML 文件显式配置或在 Java 代码中用 Transactional 注解来配置。
1 | <tx:attributes> |
Spring 提供的事务超时的配置非常简单,它会记录每个事务的开始时间和消耗时间,当特定的事件发生时会对已消耗掉的时间做校验,如果超出了配置将抛出异常。
Spring 中数据库连接被保存在线程本地变量(ThreadLocal)中,这被称作事务同步(Transaction Synchronization)。当数据库连接被保存到 ThreadLocal 时,同时会记录事务的开始时间和超时时间。所以通过数据库连接的代理创建的 Statement 在执行时就会校验这个时间。
EJB 的声明式事务管理的实现也是类似,实现的思路非常简单。如果事务超时非常重要,但你所使用的容器或框架不提供此功能,你也可以选择自己实现,关于事务超时并没有制定标准的 API。
Lucy 框架的1.5和1.6版不支持事务超时,但你可以通过 Spring 的事务管理达到相同的效果。
假设一个事务里有5条 Statement ,每条 Statement 执行时间是200毫秒,其它业务逻辑或框架操作的执行时间是100毫秒,那事务允许的超时时间至少应该1100毫秒(200 * 5 + 100)。
什么是 Statement 超时
Statement 超时是用来限制 Statement 的执行时间的,它的具体值是通过 JDBC API 来设置的。JDBC 驱动程序基于这个值进行 Statement 执行时的超时处理。Statement 超时是通过 JDBC API 中java.sql.Statement 类的 setQueryTimeout(int timeout) 方法配置的。不过现在的开发者已经很少直接在代码中配置它了,更多是通过框架来进行设置。
以 iBatis 为例,可以通过 SqlMapConfig.xml 中的 setting 属性defaultStatementTimeout 来设置全局的 statement 超时缺省值。你也可以通过在具体的 sql 映射文件中的 select insert update 标签的 statement 属性来覆盖。
当你用 Lucy 1.5或1.6版时,可以通过设置 queryTimeout 属性在数据源层面设置 Statement 超时。
Statement 超时的具体数值需要根据每个应用自身的情况而定,并没有推荐的配置。
JDBC 驱动中的 Statement 超时处理过程
每个数据库和驱动程序的 Statement 超时的处理也是不同的。Oracle 和 SQLServer 的工作方式比较像,MySQL 和 CUBRID 比较像。
Oracle 中的 Statement 超时处理
- 调用 Connection 的 createStatement() 方法创建一个 Statement 对象
- 调用 Statement 的 executeQuery() 方法
- Statement 通过内部绑定的 Connection 对象将查询命令发送到 Oracle 数据库
- Statement 向 Oracle 的超时处理线程 OracleTimeoutPollingThread(每个类加载器一个该线程)注册一个 Statement 用于处理超时
- 发生超时
- Oracle 的 OracleTimeoutPollingThread 调用 OracleStatement 的 cancel() 方法
- 通过 Statement 的 Connection 发送一条消息取消还在执行的查询
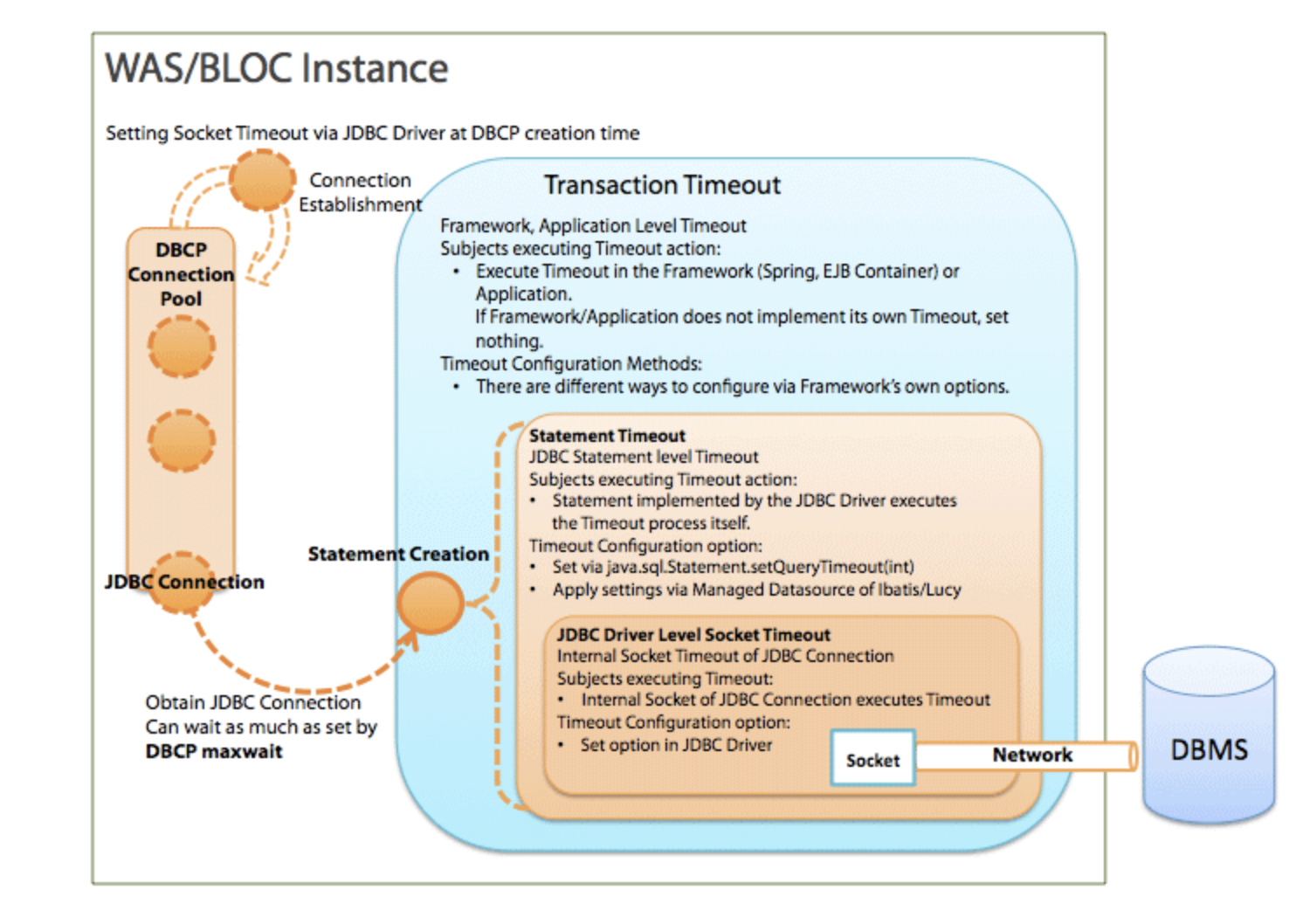
图4 Oracle 的 Statement 超时执行过程
JTDS (MS SQLServer) 中的 Statement 超时处理
1.调用 Connection 的 createStatement() 方法创建一个 Statement 对象
- 调用 Statement 的 executeQuery() 方法
- Statement 通过内部的 Connection 将查询命令发送到 MS SqlServer 数据库
- Statement 向 MS SQLServer 的 TimerThread 线程注册一个 Statement 用于处理超时
- 发生超时
- TimerThread 调用 JtdsStatement 内部的 TsdCore.cancel()方法
- 通过 ConnectionJDBC 发送一条消息取消还在执行的查询
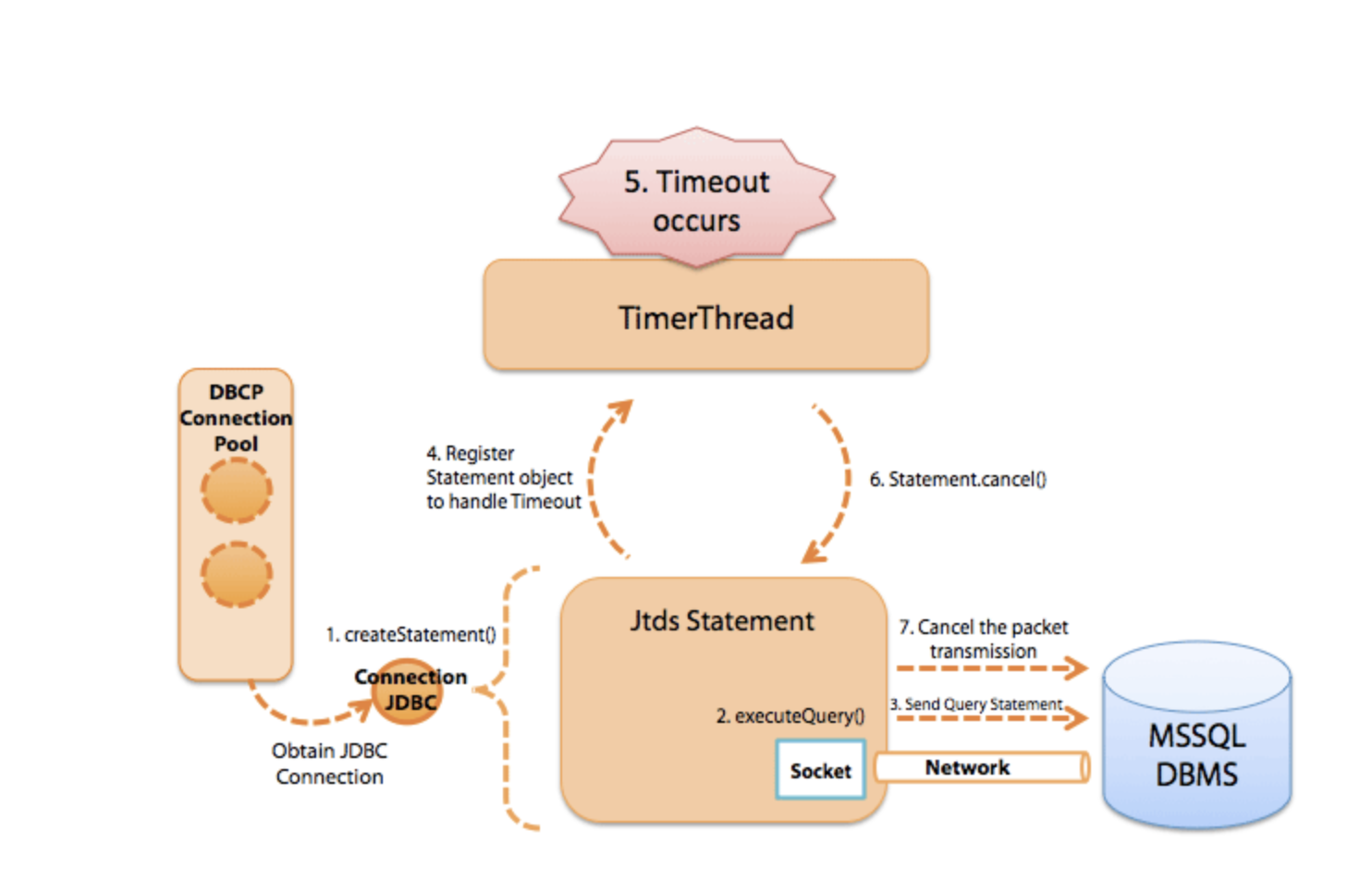
图5 MS SQLServer 的 Statement 超时执行过程
MySQL (5.0.8) 中的 Statement 超时处理
- 调用 Connection 的 createStatement() 方法创建一个 Statement 对象
- 调用 Statement 的 executeQuery() 方法
- Statement 通过内部的 Connection 将查询命令传输到 MySqlServer 数据库
- Statement 创建一个新的超时执行线程(timeout-execution)来处理超时
- 5.1以上版本改为每个连接分配一个线程
- 向 timeout-execution 线程注册当前的 Statement
- 发生超时
- timeout-execution 线程创建一个相同配置的 Connection
- 用新创建的 Connection 发送取消查询的命令
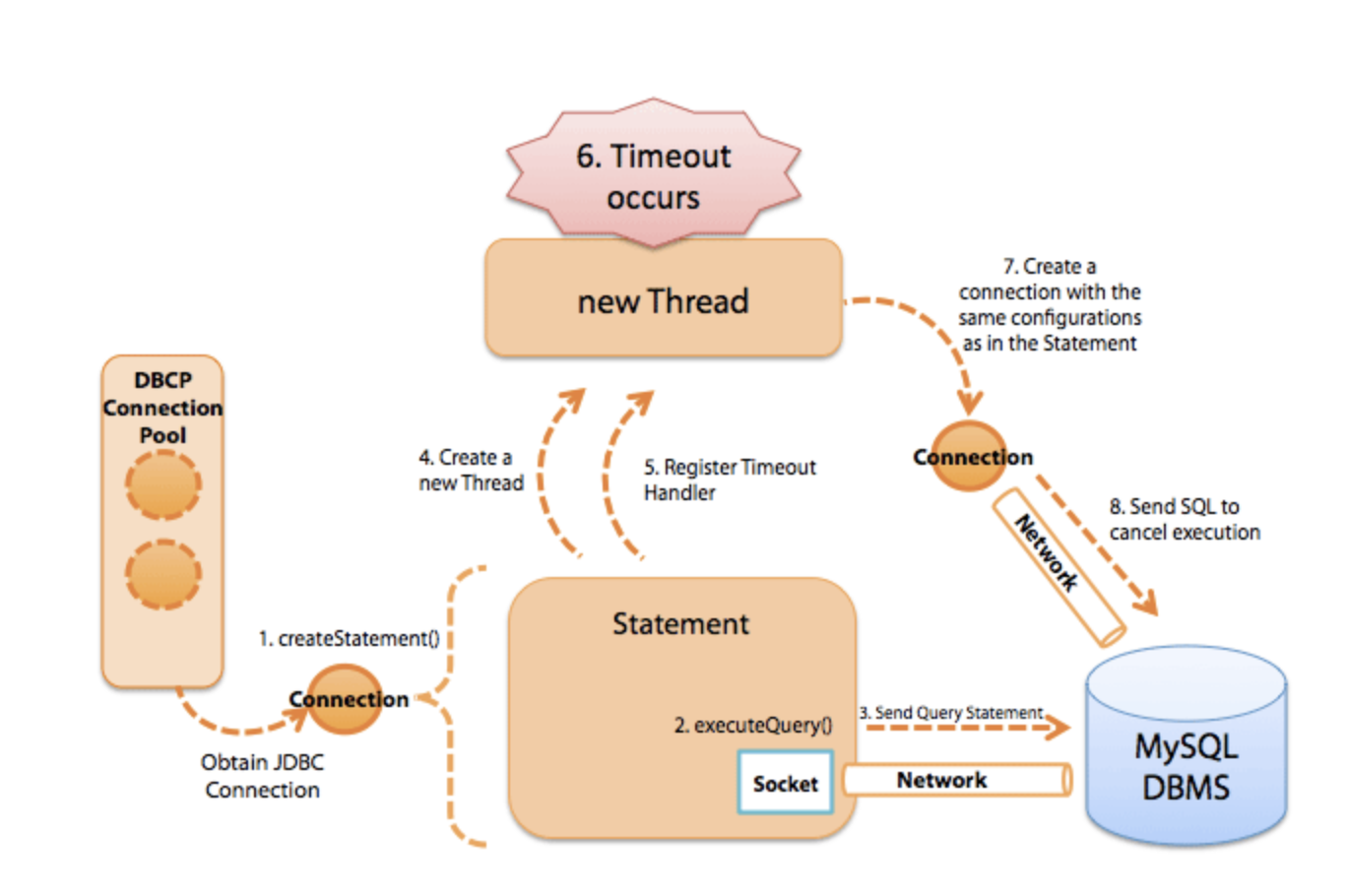
图6 MySQL 的 Statement 超时执行过程
CUBRID中的 Statement 超时处理
- 调用 Connection 的 createStatement() 方法创建一个 Statement 对象
- 调用 Statement 的 executeQuery() 方法
- Statement 通过内部的 Connection 将查询命令发送到 CUBRID 数据库
- Statement 创建一个新的超时执行线程(timeout-execution)来处理超时
- 向 timeout-execution 线程注册当前的 Statement
- 发生超时
- timeout-execution 线程创建一个相同配置的Connection
- 用新创建的 Connection 发送取消查询的命令
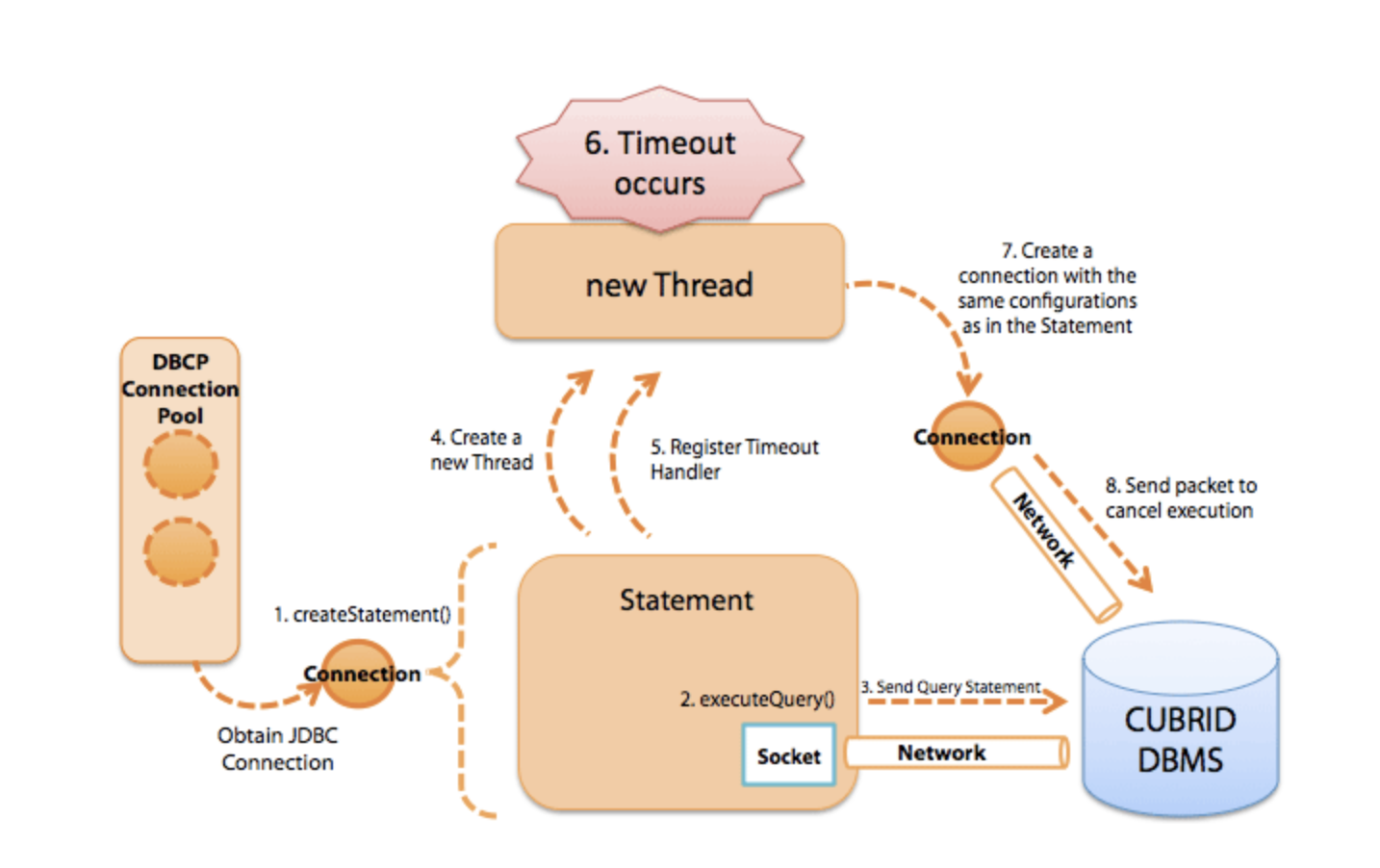
图7 CUBRID 的 Statement 超时执行过程
什么是 Socket 超时
类型4的 JDBC 驱动是用 Socket 方式与数据库连接的,应用程序和数据库之间的连接超时并不是由数据库处理的。
当数据库突然宕掉或发生网络错误(设备故障等)时,JDBC 驱动的 Socket 超时的值是必须的。由于 TCP/IP 的结构,Socket 没有办法检测到网络错误,因此应用不能检测到与数据库到连接断开了。如果没有设置 Socket 超时,应用程序会一直等待数据库返回结果。(这个连接也被叫做“死连接”) 为了避免死连接,Socket 必须要设置超时时间。Socket 超时可以通过 JDBC 驱动程序配置。通过设置 Socket 超时,可以防止出现网络错误时一直等待的情况并缩短故障时间。
不推荐使用 Socket 超时来限制一个 Statement 的执行时间,因此Socket 超时的值必须要高于 Statement 的超时时间,否则 Socket 超时将会先生效,这样 Statement 超时就没有意义,也无法生效。
下面展示了 Socket 超时设置的连个选项,其配置因不同的驱动而异。
- Socket 连接时的超时:通过 Socket 对象的 connect(SocketAddress endpoint, int timeout) 方法来配置
- Socket 读写时的超时:通过 Socket 对象的 setSoTimeout(int timeout) 方法来配置
通过查看CUBRID,MySQL,MS SQL Server (JTDS) 和 Oracle 的JDBC 驱动源码,我们确认以上所有驱动都是使用上面的2个 API 来设置socket 超时的。
下面列出了如何配置 Socket 超时
| JDBC 驱动 | 连接超时配置 | Socket 超时配置 | JDBC Url 格式 | 示例 |
|---|---|---|---|---|
| MySQL | connectTimeout(默认值:0,单位:毫秒) | socketTimeout(默认值:0,单位:ms) | jdbc:mysql://[[host:port],[host:port]…/[database]] [?propertyName1][=propertyValue1][&propertyName2][=propertyValue2]… |
jdbc:[mysql://xxx.xx.xxx.xxx:3306/database?connectTimeout=60000&socketTimeout=60000] |
| MS-SQL , jTDS | loginTimeout(默认值:0,单位:秒) | socketTimeout(默认值:0,单位:s) | jdbc:jtds:<server_type>://<server>[:<port>][/<database>][;<property>=<value>[;…]] | jdbc:jtds:sqlserver://server:port/database;loginTimeout=60;socketTimeout=60 |
| Oracle | oracle.net.CONNECT_TIMEOUT (默认值:0,单位:毫秒) | oracle.jdbc.ReadTimeout(默认值:0,单位:毫秒) | 不支持通过url配置,只能通过OracleDatasource.setConnectionProperties() API设置,使用DBCP时可以调用BasicDatasource.setConnectionProperties()或BasicDatasource.addConnectionProperties()进行设置 | |
| CUBRID | 无单独配置项(默认值:5,000,单位:毫秒) | 无单独配置项(默认值:5,000,单位:毫秒) |
- connectTimeout 和 socketTimeout 的默认值是 0 ,这意味着不会发生超时。
- 你也可以通过属性进行配置,而无需直接使用 DBCP 的 API 。
通过属性进行配置时,需要传入的 key 为 “connectionProperties”,其 value 的格式为” [propertyName=property;]*”。下面是 iBatis 中通过 xml 文件配置属性的例子。
1 | <transactionManager type="JDBC"> |
操作系统层面的 Socket 超时配置
如果没设置 Socket 超时或连接超时,应用程序多数情况下无法检测到网络错误。此时,应用程序将一直等待下去,直到连接上数据库或能读取到数据。然而,如果查看实际服务遇到的实际情况会发现问题常常在在应用程序(WAS)在30分钟后尝试重新连接到网络后被解决了。这是因为操作系统也配置了 Socket 超时时间。我公司使用的 Linux 服务器将 Socket 超时时间设置为30分钟。它将在操作系统层面对网络连接做校验。因为公司的 Linux 服务器的 KeepAlive 检查周期为30分钟,因此即使应用程序里将 Socket 超时设置为0,由网络原因引起的数据库网络连接问题也不会超过30分钟。
通常,应用程序会在调用 Socket 的 read() 方法时由于网络问题而阻塞住。然而很少在调用 Socket 的 write() 方法时处于等待状态,这取决于网络构成和错误类型。当应用程序调用 Socket 的 write() 方法时,数据被记录到操作系统的内核缓冲区,然后将控制权立即交还给应用程序。因此,一旦数据已经写入内核缓冲区,write() 的调用始终是成功。但是,如果操作系统内核缓冲区由于特殊的网络错误而满了的话,write() 方法也会进入等待状态。这种情况下,操作系统会尝试重新发送数据包一段时间,并在达到超时限制时产生错误。 在公司的 Linux服务器上这种情况的超时时间设置为15分钟。
至此,我已经解释了 JDBC 的内部操作,希望这将帮助你正确的超时配置超时时间从而减少错误。
至此,我已经对JDBC的内部操作做了讲解,希望能够让大家学会如何正确的配置超时时间,从而减少错误的发生。