当前大数据发展有三大趋势: 数据仓库往数据湖方向发展、批处理往流式处理发展、本地部署往云模式发展。数据湖作为最近两年兴起的热点概念,各大互联网公司都在对其研究和探索。本文参考了阿里、腾讯和网易等公司的一些资料,将告诉你数据湖到底是什么?有什么用?
https://xie.infoq.cn/article/7f01991ac2f3b6ef0423be513
引言
当前大数据发展有三大趋势: 数据仓库往数据湖方向发展、批处理往流式处理发展、本地部署往云模式发展。数据湖作为最近两年兴起的热点概念,各大互联网公司都在对其研究和探索。本文参考了阿里、腾讯和网易等公司的一些资料,将告诉你数据湖到底是什么?有什么用?
一、数据湖与数据仓库
数据湖与数据库、数据仓库一样,都是一种对数据组织方式的描述(无关具体技术实现)。
1.数据湖到底是什么
数据湖作为近年新造的一个概念词汇,并没有一个完全标准化的定义。我们来看看业界的主流定义:
维基百科的定义
数据湖(Data Lake)是指使用大型二进制对象或文件这样的自然格式储存数据的系统。它通常把所有的企业数据统一存储,既包括源系统中的原始副本,也包括转换后的数据,比如那些用于报表,可视化, 数据分析和机器学习的数据。数据湖可以包括关系数据库的结构化数据(行与列)、半结构化的数据(CSV,日志,XML,JSON),非结构化数据 (电子邮件、文件、PDF)和 二进制数据(图像、音频、视频)。
AWS 的定义
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
阿里云的定义
数据湖是统一存储池,可对接多种数据输入方式,您可以存储任意规模的结构化、半结构化、非结构化数据。数据湖可无缝对接多种计算分析平台,直接进行数据处理与分析,打破孤岛,洞察业务价值。同时,数据湖提供冷热分层转换能力,覆盖数据全生命周期。
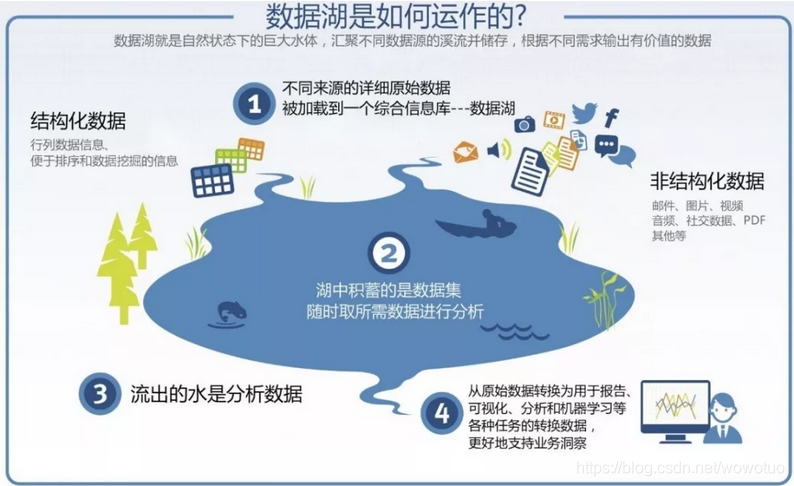
上面的定义还是比较抽象,这里有个更形象贴切的定义:数据湖就是自然状态下的巨大水体,汇聚不同数据源的溪流并存储,根据不同需求输出有价值的数据。既可以存储结构化数据,也可以存储非结构化数据;既可以接入离线批数据,也可以接入实时流数据;既可以支持流/批计算引擎,也可以支持交互式分析引擎和机器学习引擎。
2.数据湖的特点
一般而言,数据湖技术需要具备以下几项特点[1]:
- 支持多种计算引擎、同时支持流批处理
- 支持多种存储引擎
- 支持数据更新
- 支持事务(ACID)
- 可扩展的元数据
- 数据质量保障
上面并没有列出支持非结构化数据这一特点(HDFS 本身就已可以实现),业界对于数据湖的关注点更多是在结构化和半结构化数据的存储和计算上,例如如何通过数据湖技术将实时数仓和离线数仓融合。
3.数据湖与数据仓库的区别
数据仓库和数据湖在各个维度上的区别对比[2]:

上面的对比看看就好,数据湖在实际应用中,并不需要与数据仓库完全对立开来,通常与数据仓库结合起来形成所谓“湖仓一体”[3]。
二、开源数据湖方案介绍
目前并没有针对数据湖的比较成熟的解决方案,几个大厂在开发相关技术来解决内部遇到的一些痛点后,开源了几个项目,比较著名的有 Databrics 的 Dalta Lake,Uber 开源的 Hudi,Netflix 开源的 Iceberg,俗称“数据湖三剑客”。
1.数据湖三剑客
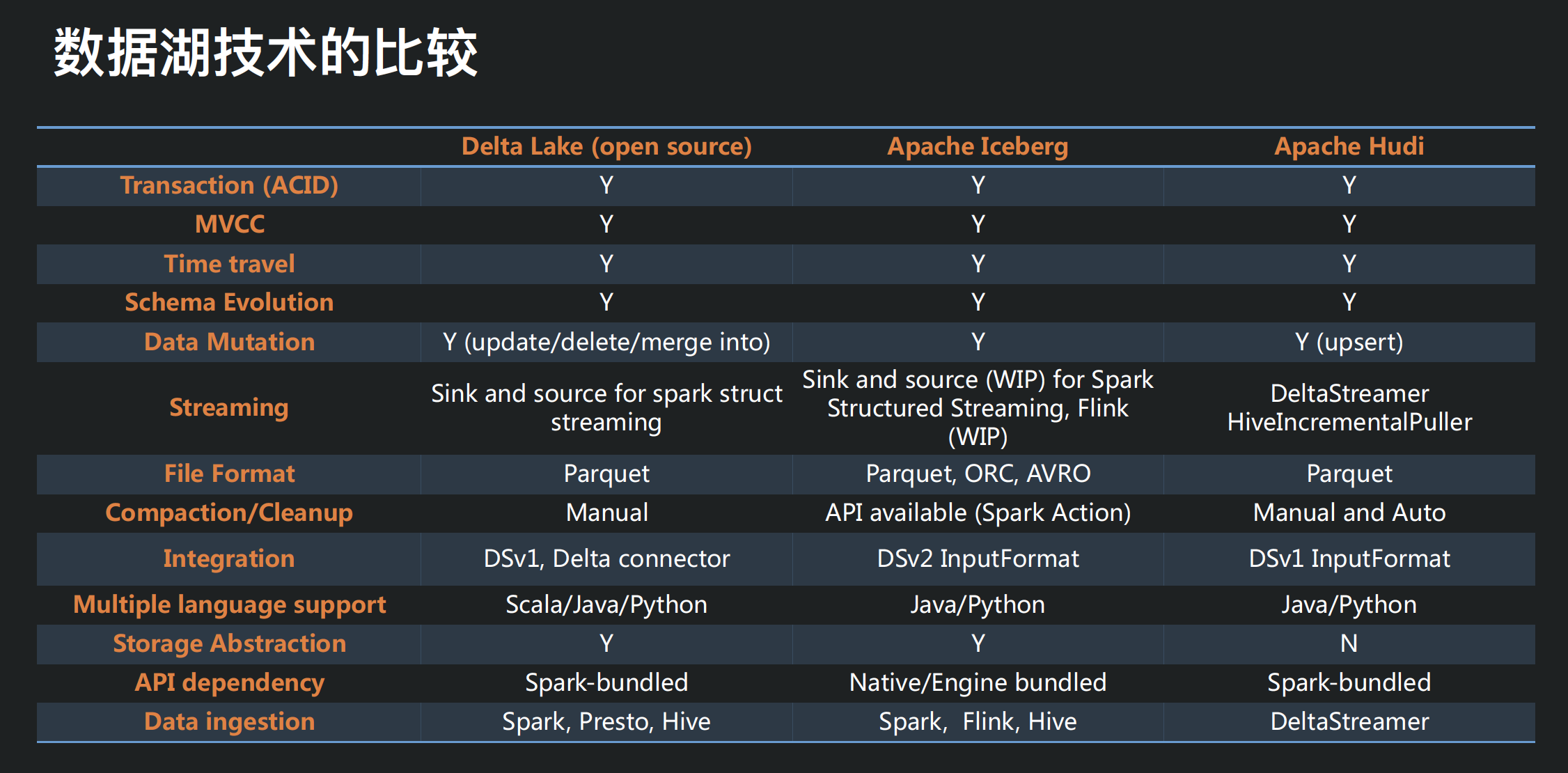
需要注意的一点是,目前各个数据湖技术仍在处在初期快速迭代阶段,最新版本都还是 0.X 版本(截止发文时 21 年 3 月):
- Delta Lake 0.8.0
- Hudi 0.7.0
- iceberg-0.11.0
2.Iceberg 介绍
Iceberg 的设计之初就并未绑定于某一特定引擎,它实现了通用的数据组织格式,利用此格式可以方便地与不同引擎(如 Flink、Hive、Spark)对接。
Iceberg 本质上是一种专为海量分析设计的表格式标准,可为主流计算引擎提供高性能的读写和元数据管理能力。(来自Iceberg官网的定义是:Apache Iceberg is an open table format for huge analytic datasets.)
所谓的 table format,其实就是 Hadoop 中的 Metastore 所扮演的角色。功能包含表 schema 定义、表中文件的组织形式、表相关统计信息、索引信息以及表的读写 API 实现[4]。
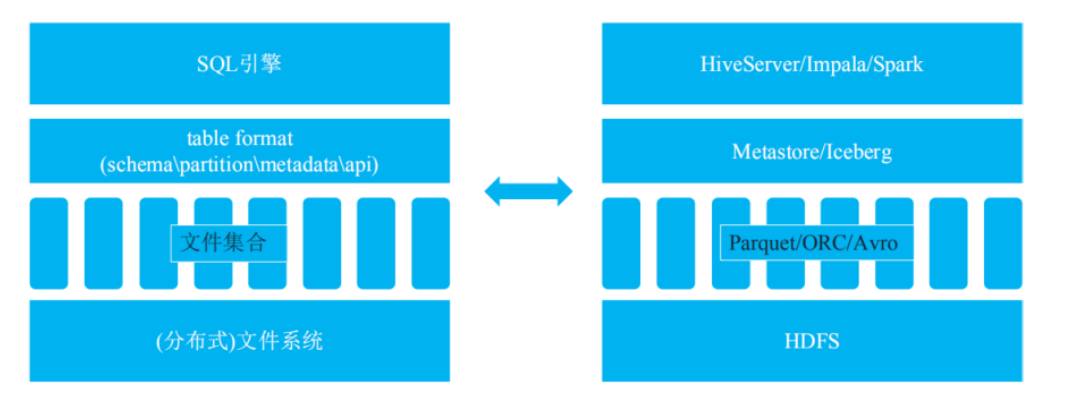
Iceberg 相对于 Metastore 的优势:
- 新 partition 模式:分区作为一个字段存储而不是文件夹,避免了查询时多次调用 namenode 的 list 方法,降低 namenode 压力,提升查询性能
- 新 metadata 模式:文件级别列统计信息可以用来根据 where 字段进行文件过滤,很多场景下可以大大减少扫描文件数,提升查询性能
- 新 API 模式:实现存储批流一体
Iceberg 读写 API 的实现:
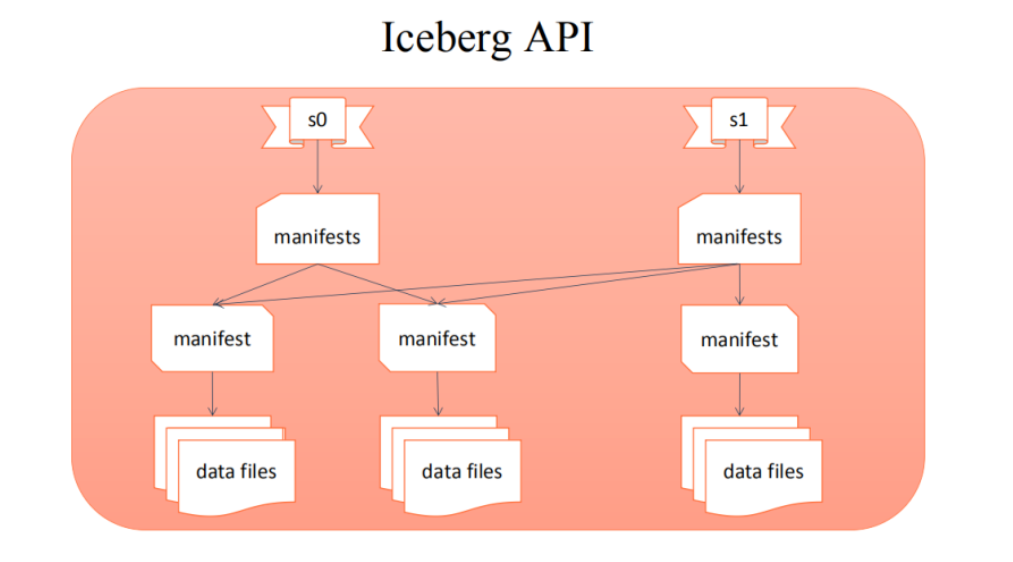
上层业务写好一批文件,调用 iceberg 的 commit 接口提交本次的写入形成一个新的 snapshot 快照。这种提交方式保证了表的 ACID 语义。同时基于 snapshot 快照提交可以实现增量拉取实现。
数据湖写入流数据时,实际都是将流数据转换为微批(minibatch)进行处理,所以实时性会比真正的流式计算差些,延迟可能达到分钟级。
(更多介绍可另参考:网易:Flink + Iceberg 数据湖探索与实践[4])
3.Hudi 介绍
Hudi官网:Apache Hudi ingests & manages storage of large analytical datasets over DFS (hdfs or cloud stores).
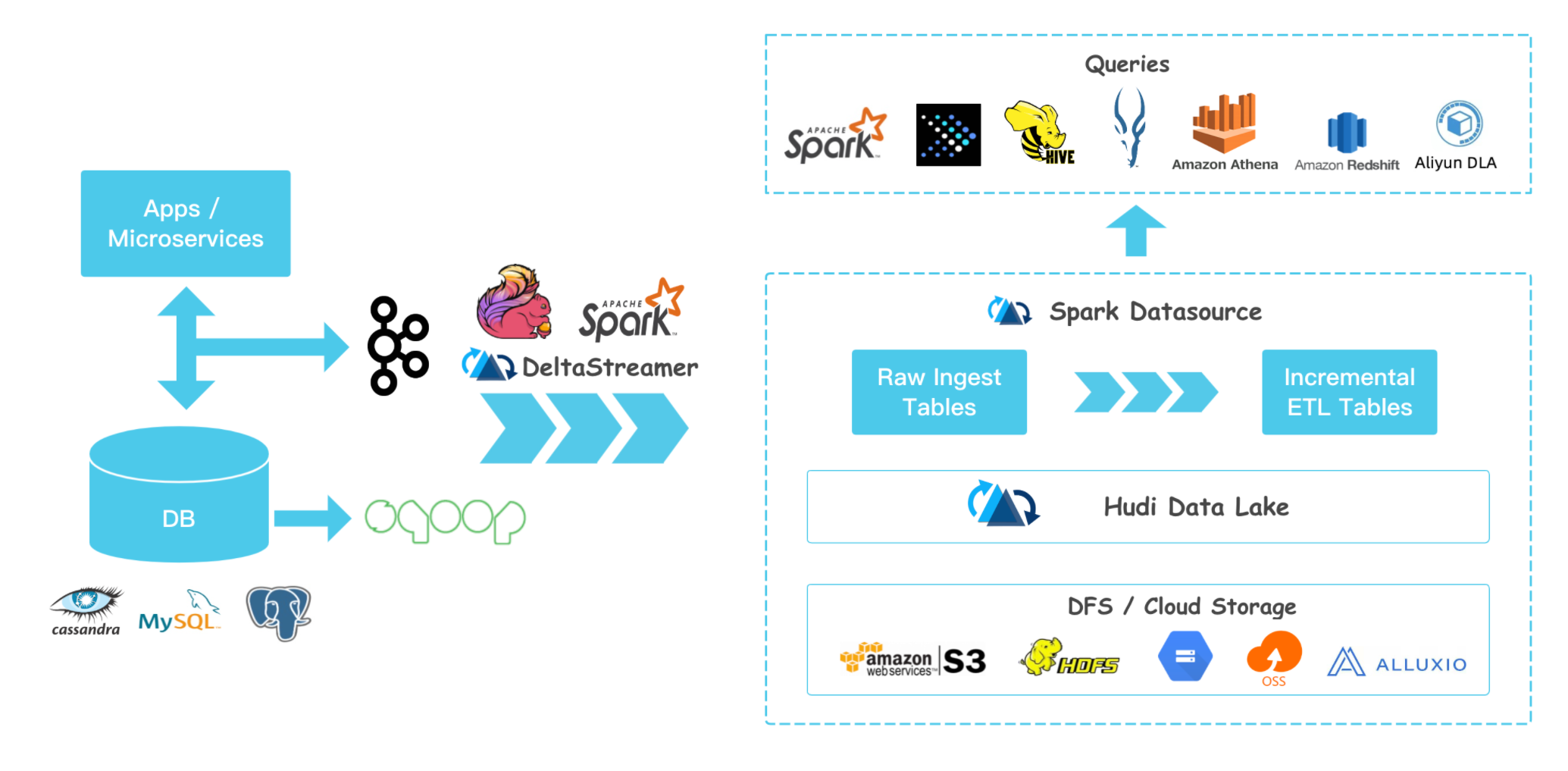
Hudi 设计之初是与 Spark 引擎强耦合的,在去年下半年进行了与 Spark 解耦,最新的 Hudi0.70 已经增加了对 Flink 的支持[5]。
Hudi 提供了两种原语,使得除了经典的批处理之外,还可以在数据湖上进行流处理。这两种原语分别是:
- Update/Delete 记录:Hudi 使用细粒度的文件/记录级别索引来支持 Update/Delete 记录,同时还提供写操作的事务保证。查询会处理最后一个提交的快照,并基于此输出结果。
- 变更时间轴:Hudi 对获取数据变更提供了一流的支持:可以从给定的时间点获取给定表中已 updated/inserted/deleted 的所有记录的增量流,并解锁新的查询类别。
(更多介绍可另参考:Apache Hudi 设计与架构最强解读[6])
4.Delta Lake 介绍
Delta Lake 官网:Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark™ and big data workloads.
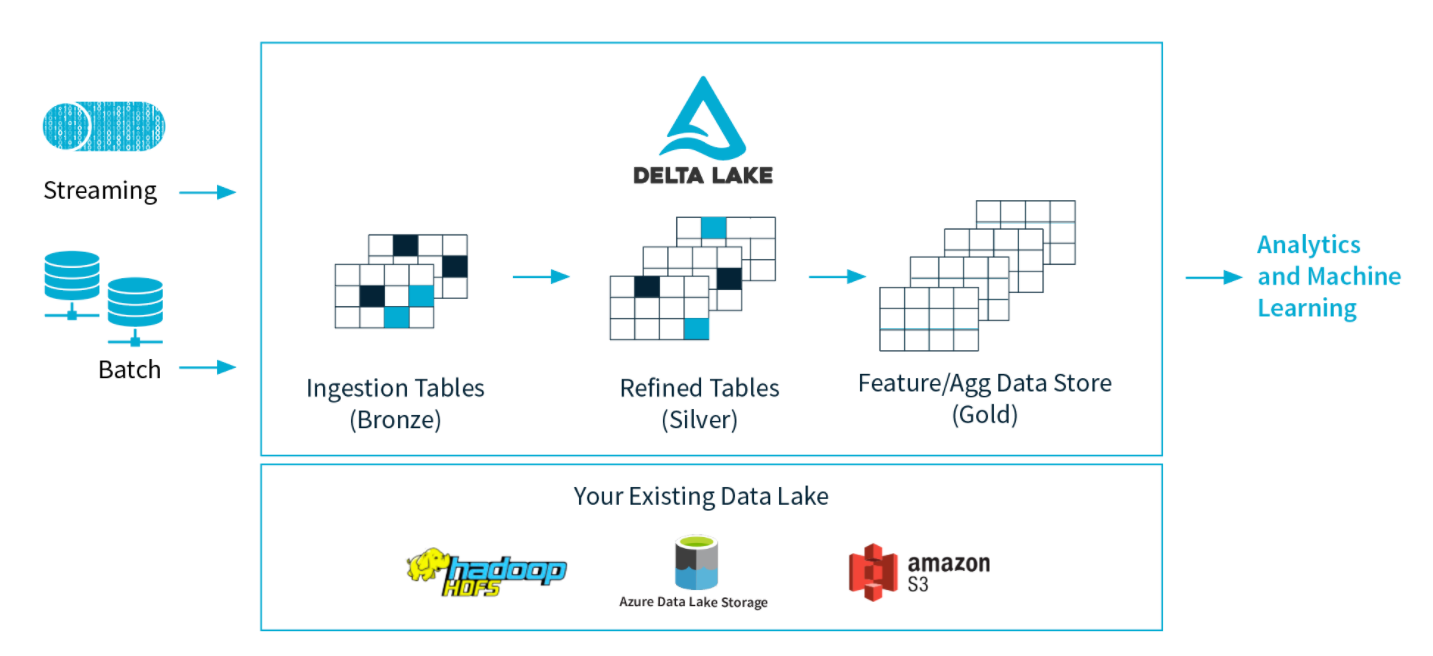
Delta Lake 是 Spark 计算框架和存储系统之间带有 Schema 信息的存储中间层。(可以看到 DeltaLake 是与 Spark 强耦合的)
它有一些重要的特性:
- 设计了基于 HDFS 存储的元数据系统,解决 metastore 不堪重负的问题;
- 支持更多种类的更新模式,比如 Merge / Update / Delete 等操作,配合流式写入或者读取的支持,让实时数据湖变得水到渠成;
- 流批操作可以共享同一张表;
- 版本概念,可以随时回溯,避免一次误操作或者代码逻辑而无法恢复的灾难性后果。
Delta Lake 是基于 Parquet 的存储层,所有的数据都是使用 Parquet 来存储,能够利用 parquet 原生高效的压缩和编码方案。
Delta Lake 在多并发写入之间提供 ACID 事务保证。每次写入都是一个事务,并且在事务日志中记录了写入的序列顺序。
事务日志跟踪文件级别的写入并使用乐观并发控制,这非常适合数据湖,因为多次写入/修改相同的文件很少发生。在存在冲突的情况下,Delta Lake 会抛出并发修改异常以便用户能够处理它们并重试其作业。[2]
三、数据湖应用场景探索
1.构建流批一体的实时数仓
上文中可以看到,“流批一体的存储”是数据湖技术都重点关注的一个特性。利用这个特性,可以将目前实时数仓常用的 Lambda 改造为 Kappa 架构,解决实时数仓的诸多问题。
Lambda 数仓架构
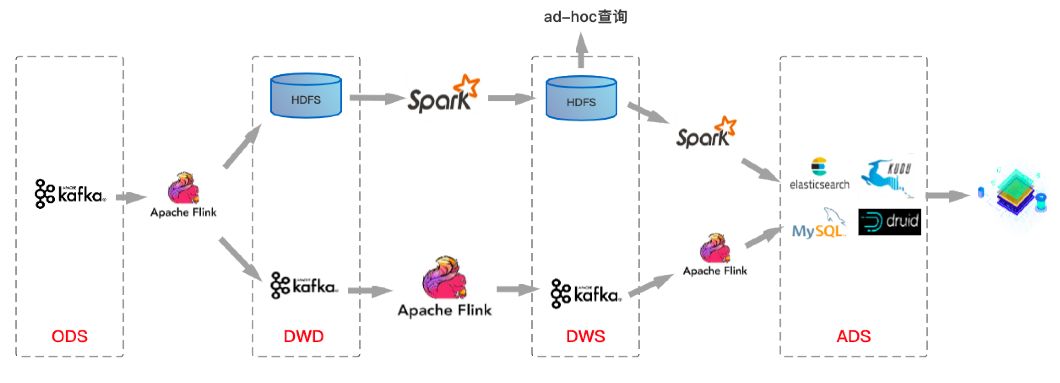
基于 Lambda 架构建设的实时数仓存在较多的问题。如上图的这个架构图,第一条链路是基于 kafka 中转的一条实时链路(秒级),另一条是离线链路(天级),甚至有些公司会有第三条准实时链路(15 分钟~1 小时)。
- 两条链路对应两份数据,很多时候实时链路的处理结果和离线链路的处理结果对不上。
- Kafka 无法存储海量数据, 无法基于当前的 OLAP 分析引擎高效查询 Kafka 中的数据。
- Lambda 维护成本高。代码、数据血缘、Schema 等都需要两套。运维、监控等成本都非常高。
Kappa 数仓架构
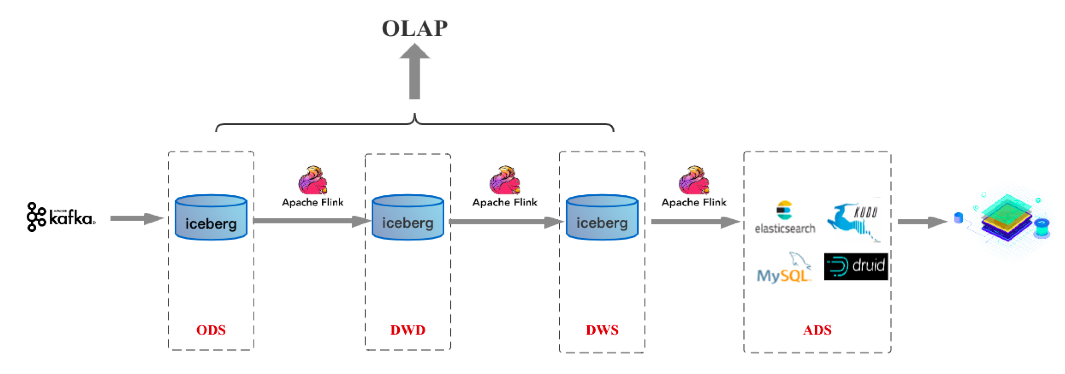
以 Flink + Iceberg 构建数据湖为例,Flink 实现计算引擎层面的流批一体,Iceberg 实现存储层面的流批一体。计算+存储两个层面实现流批统一,可极大地降低实时数仓的开发和维护成本。
2.提升 ETL 任务的执行性能
还是以 Iceberg 为例,新 Partition 模式下不再需要请求 NameNode 的分区信息,同时得益于文件级别统计信息模式下可以过滤很多不满足条件的数据文件,可以大大提升 ETL 任务执行的效率[4]。
更多大数据领域干货笔记,搜索关注公众号:关二爷大数据笔记****(bigdata_guanerye)。
参考资料
[1] 数据湖技术 Iceberg 的探索与实践——邵赛赛(腾讯数据湖负责人)
[2] 计算引擎之下,存储之上 - 数据湖初探:https://mp.weixin.qq.com/s/MEhbm3Tyvms1ohwg4O8Umg
[3] 数据湖 VS 数据仓库之争?阿里提出大数据架构新概念:湖仓一体:https://developer.aliyun.com/article/775390
[4] 网易:Flink + Iceberg 数据湖探索与实践:https://developer.aliyun.com/article/776257
[5] Apache Hudi meets Apache Flink:https://hudi.apache.org/blog/apache-hudi-meets-apache-flink/
[6] Apache Hudi 设计与架构最强解读:https://mp.weixin.qq.com/s/KbKKclT3oaNEnU--OI3f4Q