背景
某些特殊场景下,MySQL需要跨库进行查询。
MySQL可以像Oracle一样,通过”DBLink“实现跨库查询。
“DBLink”之所以用引号是因为mysql没有dblink的功能,而是通过 “FEDERATED” 来实现跨库操作的;
FEDERATED存储引擎访问在远程数据库的表中的数据,而不是本地的表。这个特性给某些开发应用带来了便利,你可以直接在本地构建一个federated表来连接远程数据表,配置好了之后本地表的数据可以直接跟远程数据表同步。实际上这个引擎里面是不真实存放数据的,所需要的数据都是连接到其他MySQL服务器上。
开启FEDERATED
检查 “FEDERATED” 是否存在并开启
1 | show engines; |
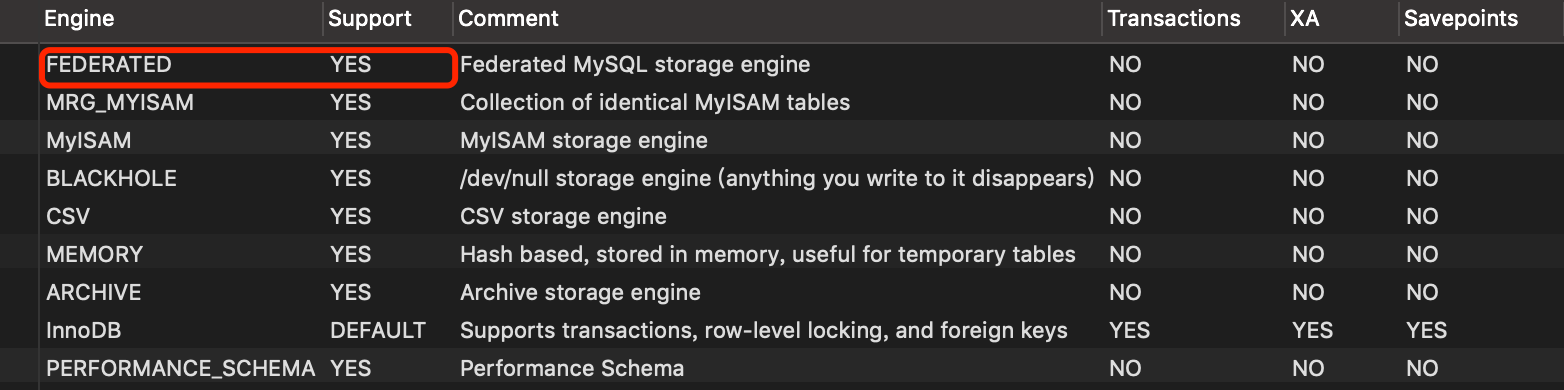
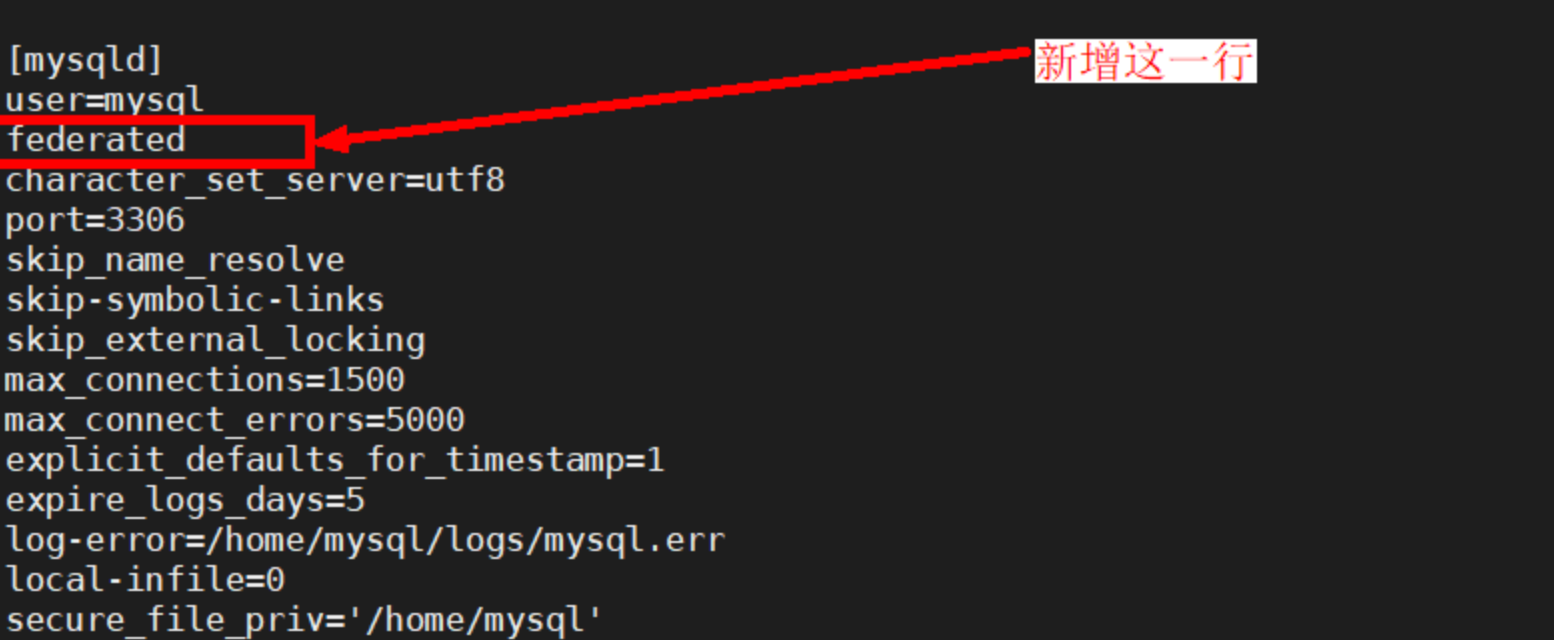
Support为“YES”表示已开启,如果没有开启,需要在MySQL配置文件中 [mysqld] 下面加上一行federated即可
之后我们就可以使用 FEDERATED引擎来创建跨不同数据的表创建实例了,sql如下:
1 | CREATE SERVER fedlk3 |
通过CREATE SERVER 我们将目标数据库连接保存起来,然后在创建时调用数据库连接;
这样我们的 “新增表” 创建之后,会将不同数据库内的“目标表”数据写入
注意事项
对本地虚拟表的结构修改,并不会修改远程表的结构
truncate 命令,会清除远程表数据
drop命令只会删除虚拟表,并不会删除远程表
不支持 alter table 命令
目前使用federated 最大的缺点:
select count(*), select * from limit M, N 等语句执行效率非常低,数据量较大时存在很严重的问题,但是按主键或索引列查询,则很快,如以下查询就非常慢(假设 id 为主索引)
select id from db.tablea where id >100 limit 10 ;
而以下查询就很快:
select id from db.tablea where id >100 and id<150;
如果虚拟虚拟表中字段未建立索引,而实体表中为此字段建立了索引,此种情况下,性能也相当差。但是当给虚拟表建立索引后,性能恢复正常。
类似
where name like "str%" limit 1的查询,即使在 name 列上创建了索引,也会导致查询过慢,是因为federated引擎会将所有满足条件的记录读取到本,再进行 limit 处理。
这几个问题已经严重影响了federated 在实际环境中的应用,所以这个引擎很冷门,不过在一些特定环境还是能用用的。