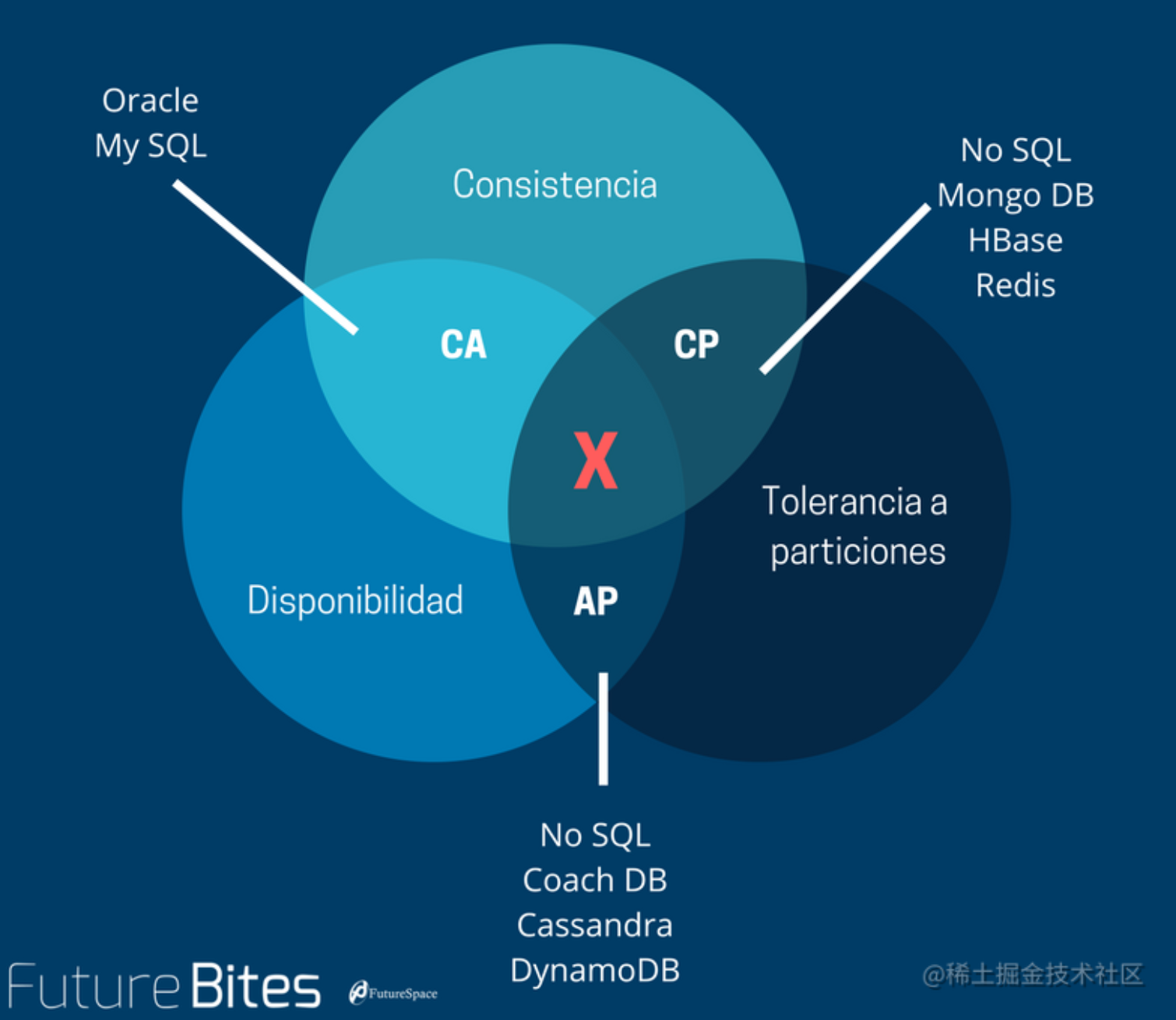
CAP原则又称CAP定理,指的是在一个分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾。
原文地址:我理解的分布式理论-CAP - 掘金
`
历史背景
时间回到 1985 年,彼时,后来证明了 CAP 理论的 Lynch 教授此时给当时的 IT 界来了一记惊雷:她通过不可辩驳的证明告诉业界的工程师们,如果在一个不稳定(消息要么乱序要么丢了)的网络环境里(分布式异步模型),想始终保持数据一致是不可能的。这是个什么概念呢?就是她打破了那些既想提供超高质量服务,又想提供超高性能服务的技术人员的幻想。这本质是在告诉大家,在分布式系统里,需要妥协。
过了15年,在2000 年时,Eric Brewer 教授在 PODC 会议上提出了 CAP 理论,但是由于没有被证明过,所以,当时只能被称为 CAP 猜想。这个猜想引起了巨大的反响,因为 CAP 很符合人们对设计纲领的预期。在 2002 年后,经过 Seth Gilbert 和 Nancy Lynch 从理论上证明了 CAP 猜想后,CAP 理论正式成为了分布式系统理论的基石之一。
概念解释
要准确的理解CAP,首先必须明白CAP中3个概念的准确定义,3个概念分别对应CAP的3个缩写 Consistency、Availability、Partition Tolerance。
Consistency 一致性
all nodes see the same data at the same time
在服务节点进行更新操作后,所有节点同一时间的数据完全一致,也称数据一致性。
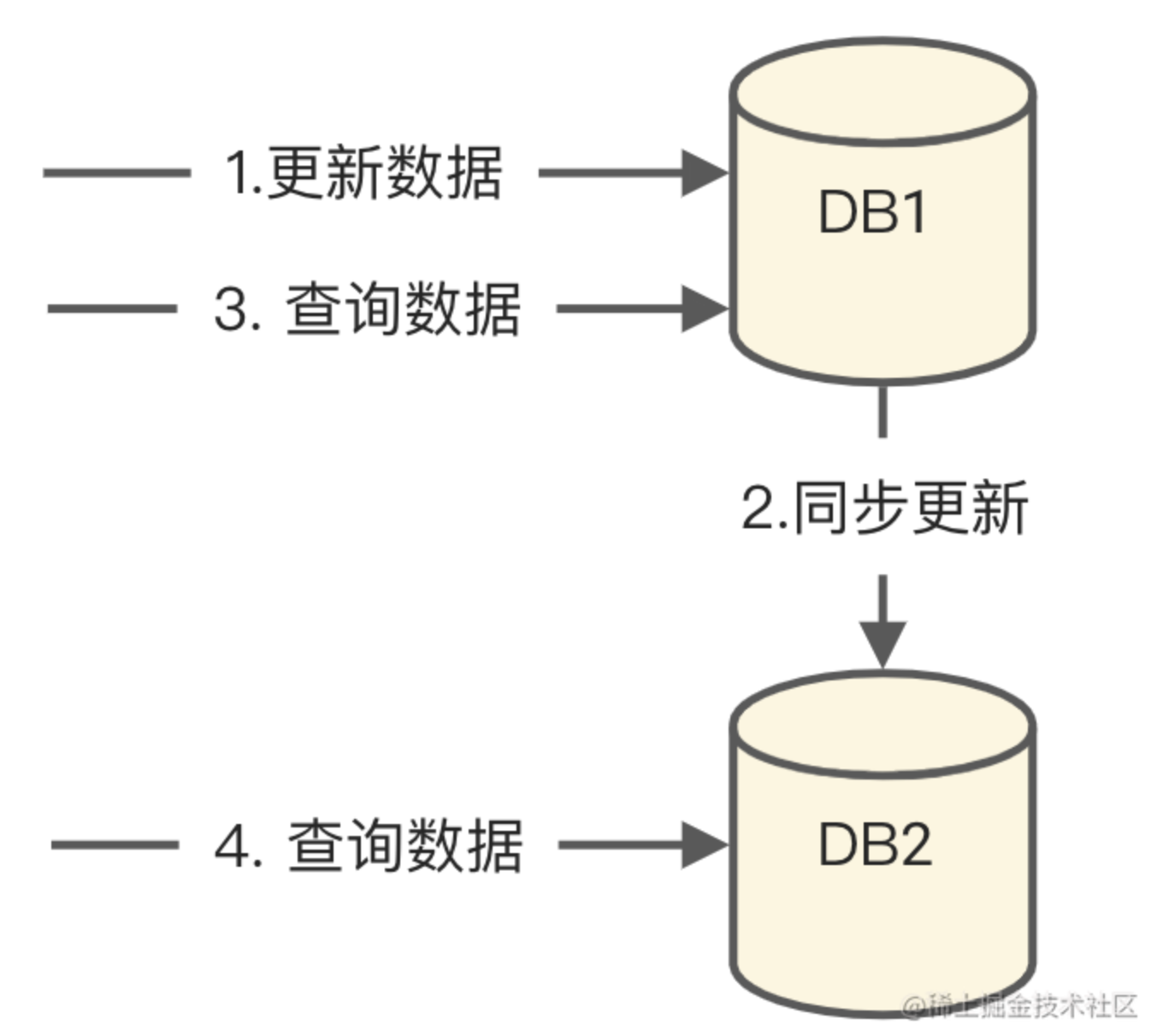
在DB1更新完成后,步骤3的查询结果一定是最新的数据,那么步骤4的查询结果必须要和3一样,不然就是数据不一致。
Availability 可靠性
Reads and writes always succeed
在预期的响应时间内,必须返回结果(非异常的)。这里有两个概念,一个是预期响应时间,一个是非异常的结果。
预期响应时间应该是早在系统设计时就定义好的,要结合业务场景的考虑,例如我们google搜索要在0.5s内返回我们想要的结果,那么0.5就是定义好的结果,
一个文件转换的服务,预期响应时间可能会是数十秒甚至以分钟计算。只要能在预期响应时间内返回,都可以算作未超时的。
非异常的结果是指能被客户端接收并进行正常后续处理的,12306抢票时刷新后看到有票,点击购买又告知没票了,刷新后看到的是旧数据,但整个流程是没有发生异常,也可以说是可靠性。
Partition Tolerance 分区容错性
分布式场景下节点间都是通过网络进行通信的,网络肯定不是100%可靠的,也会有异常的时候。
当两个节点间发生了异常不能正常通信了,就可以说这两个节点之间发生分区了。
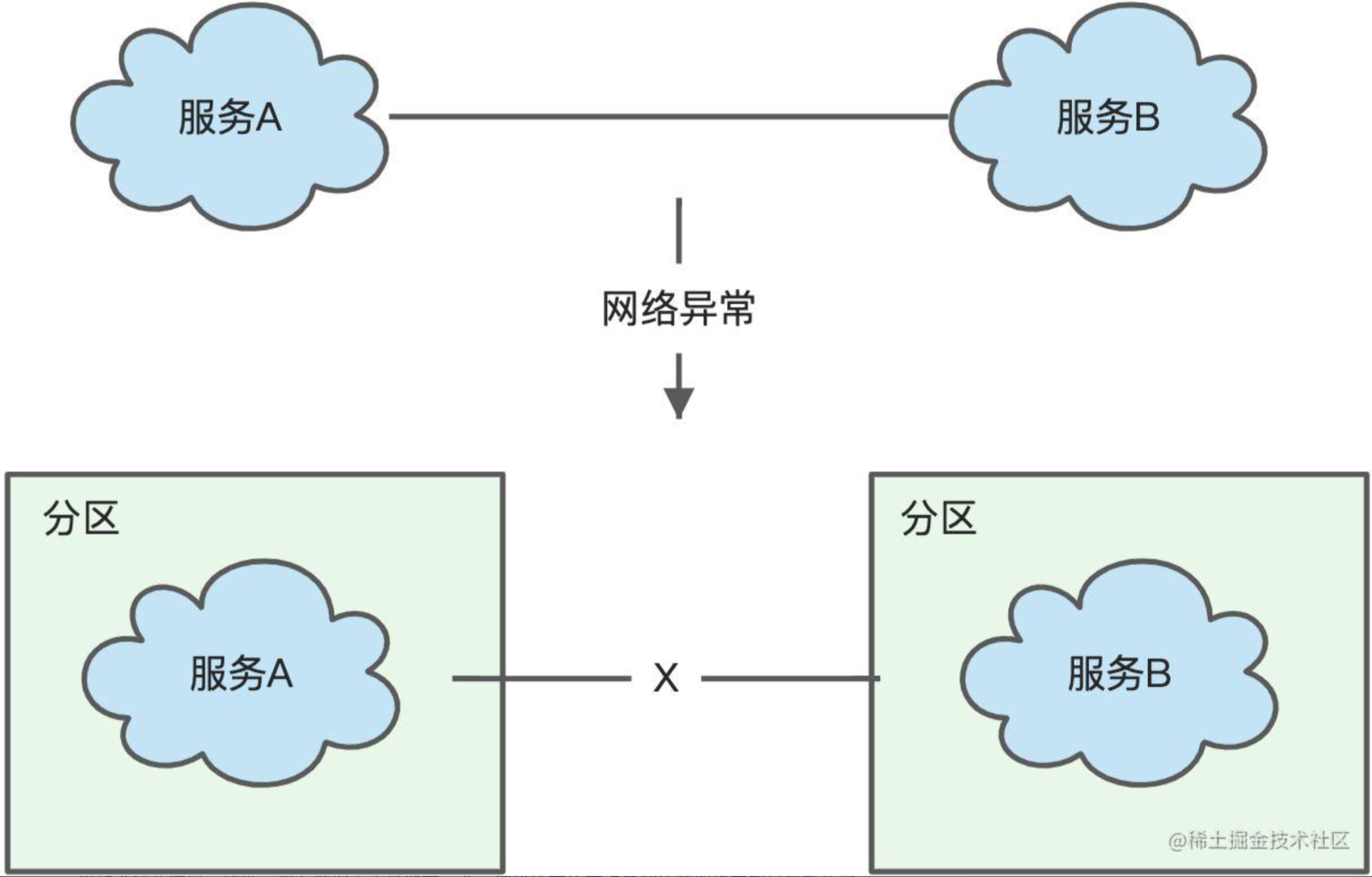
那么对于A服务而言,假设B发生异常了,A是否要容忍这种情况呢?选择不容忍,那么对应的措施就是A马上对外停止服务。这对于分布式系统来说绝对是不能接受的,所以我们必须容忍网络分区的发生,即使相关服务发生了异常,服务也不能停止运行。
这么看来CAP中P是必须要的,同时也知道CAP3这不能同时满足,现在的难题就是C和A中如何进行取舍
为什么C和A不能同时存在
假如必须要满足一致性,那么数据中心只能有一个,这样所有的节点拿到的数据肯定都是最新的了。
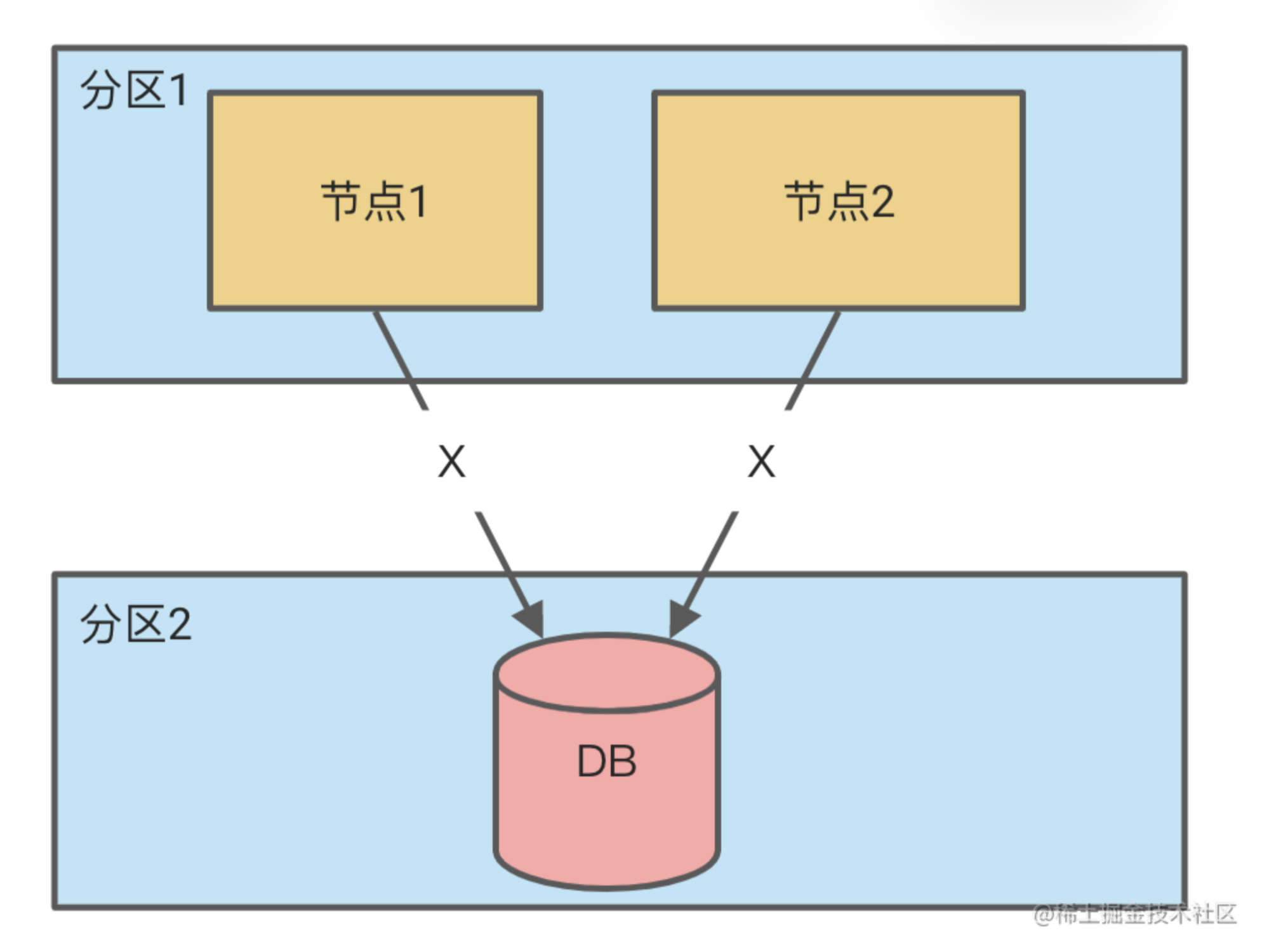
那就会有一个问题,数据中心一旦发生网络分区,就导致所有节点无法处理请求,这样可靠性必然不能保证。
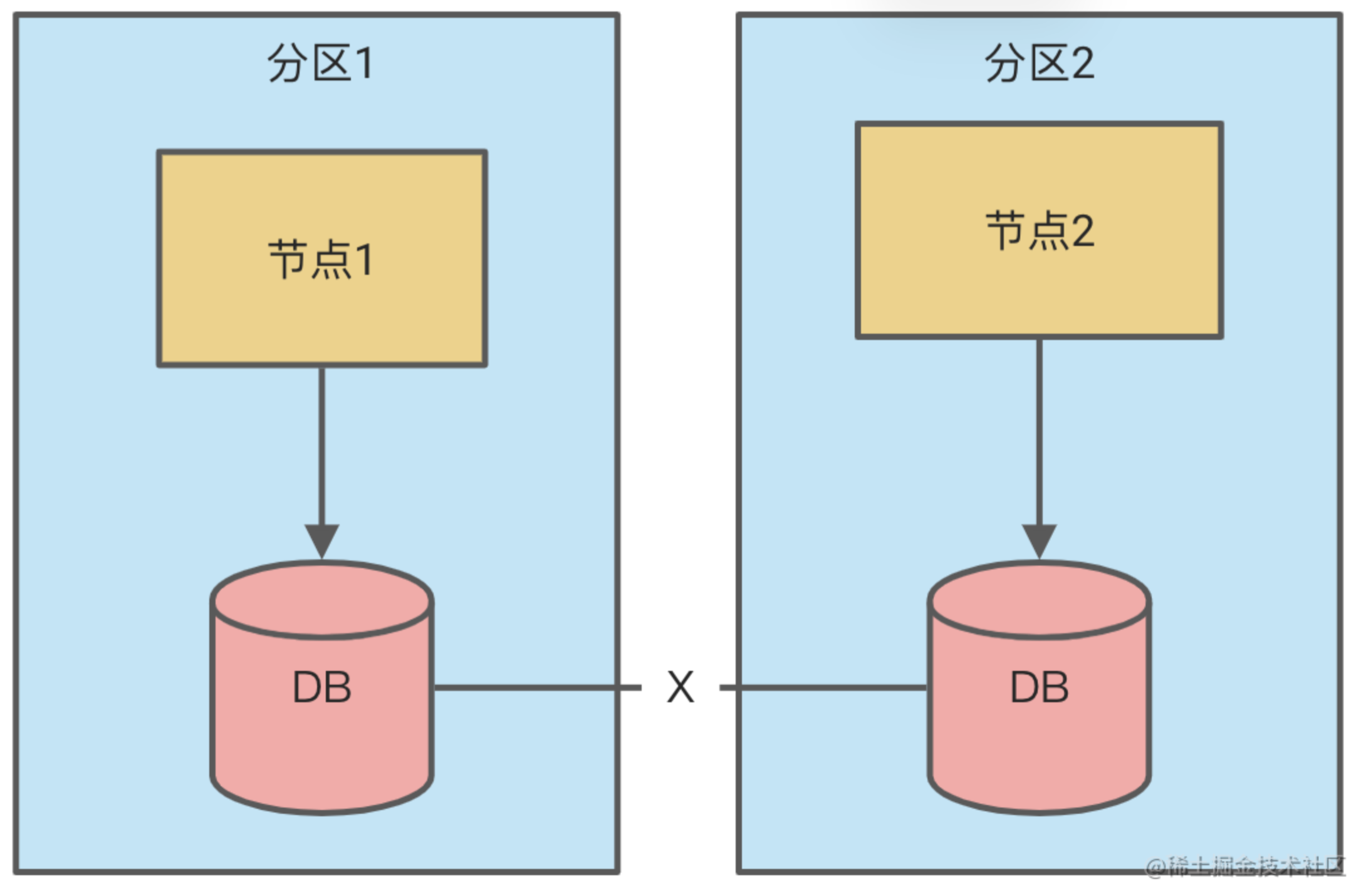
假如必须要满足可靠性,那么我们可以采用多数据中心的方式,这样即使个别节点发生网络分区,也不会导致整个服务不可用。可是这就有一个问题,最新的数据无法同步给其他分区的节点,就可能会导致数据不一下的可能。
如何取舍C和A
在没有发生网络分区的时候,CAP三者都是满足的,只有当发生网络分区这种小概率事件的时候。
先看一些开源框架是如何进行设计的
cp - Zookeeper,Redis:当zookeeper和redis会保证数据的一致性,保证任何时候获取到的数据都是最新的。
ca - Mysql,RocketMQ: 在Mysql和RocketMQ的主从架构中,当主从之间发生网络分区时,从从库获取到的数据可能是不一致的。
说到底,还是看业务场景。例如涉及到钱的系统,那么一致性是肯定要保证的,银行系统哪怕停止服务也要保证数据的一致性。用过12306,肯定遇到过页面刷新后同一车次有时候有票有时候没票的情况,这就是为了提高可用性,保证刷新操作成功,但是一致性就无法得到保证了。