用途
将excel某一区域内的数据进行统计汇总分析
随访后台做了埋点,定时将所有请求上传云端,便于分析用户行为以及接口效率,具体配置如下:
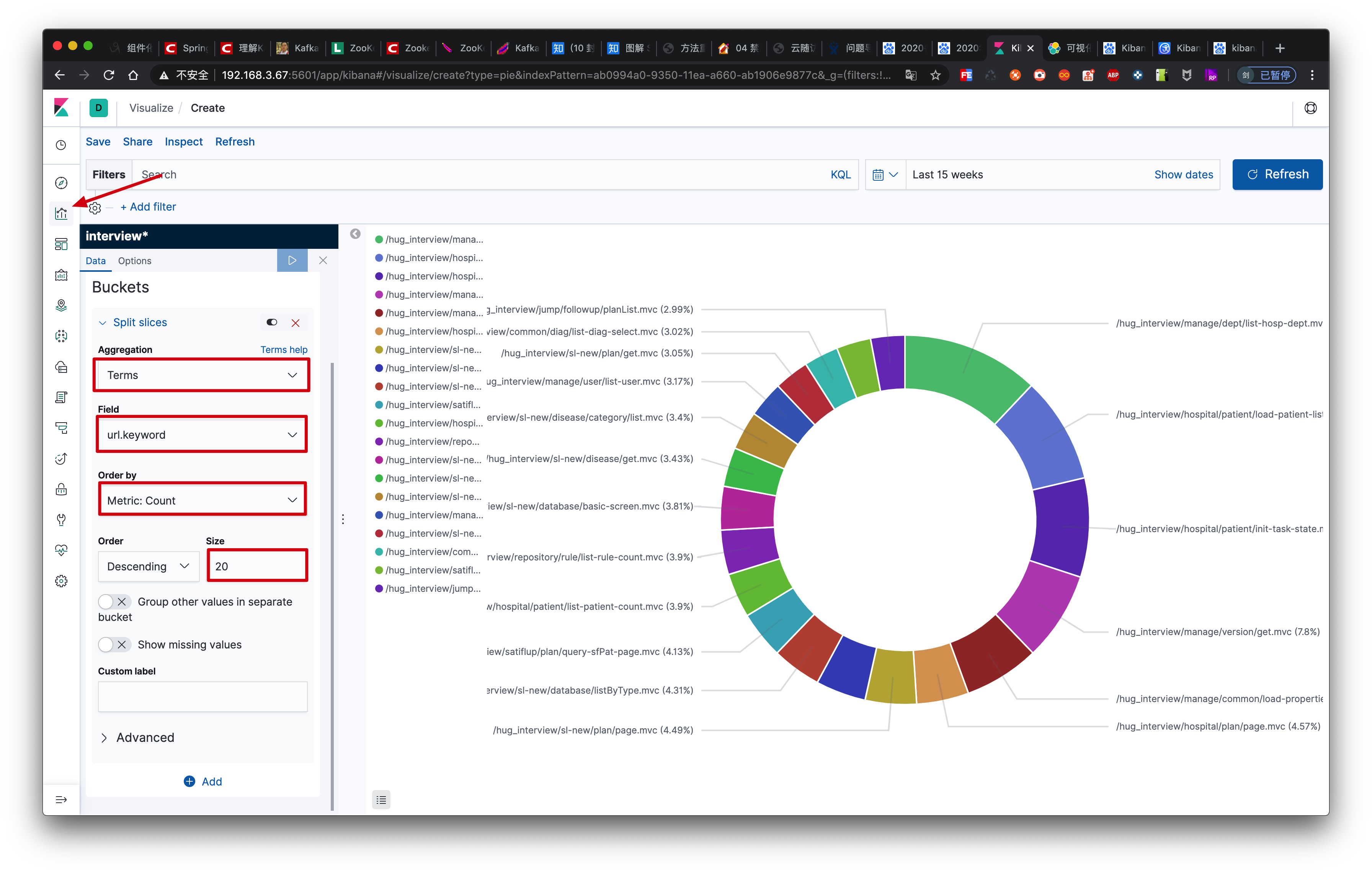
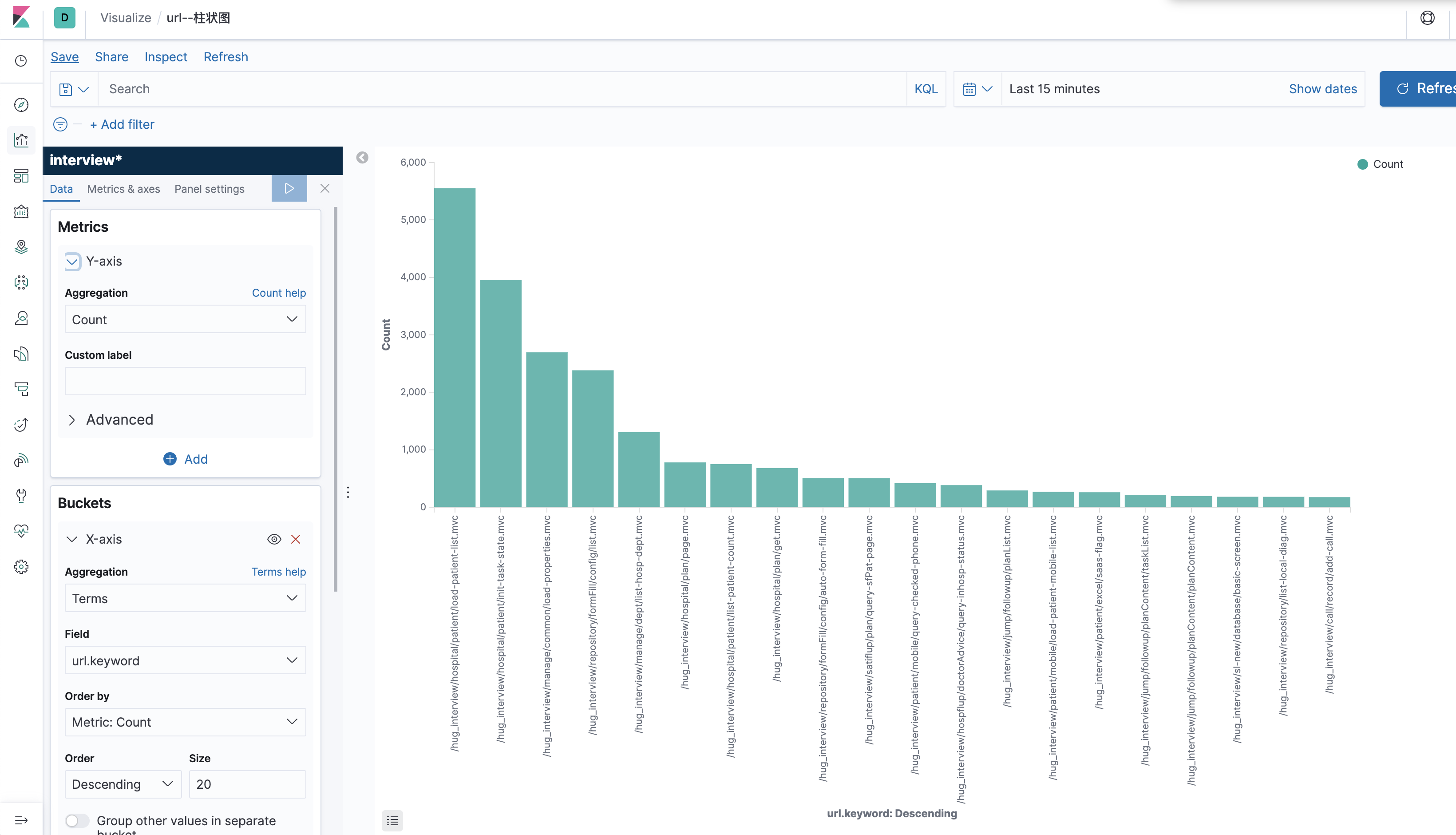
https://www.elastic.co/guide/cn/kibana/current/tutorial-visualizing.html
Tomcat启动到一半闪退,bin目录下生成了hs_err_pidXXXX.log文件
日志内容如下
1 | # |
翻译过来就是本地内存分配失败, 可能的原因有两种
查看服务器,发现内存足够,尝试按第二个问题进行解决。
禁止使用压缩指针模式,在Catalina.bat中的JAVA_OPTS的值后面加
1 | -XX:-UseCompressedOops |
线上故障主要会包括 CPU、磁盘、内存以及网络问题,而大多数故障可能会包含不止一个层面的问题,所以进行排查时候尽量四个方面依次排查一遍。同时例如 jstack、jmap 等工具也是不囿于一个方面的问题的,基本上出问题就是 df、free、top 三连,然后依次 jstack、jmap 伺候,具体问题具体分析即可。