OLAP和OLTP
OLTP(On-Line Transaction Processing):联机事务处理,典型代表是关系型数据库(mysql),它的数据存储在服务器本地的文件里
OLAP(On-Line Analytical Processing):联机分析处理,OLAP型数据库的典型代表是分布式文件系统(hive),它的数据存储在HDFS集群里
它们的主要区别入下图:

数据从何而来?
企业日常的各个环节都会产生数据,一个企业从小到大的过程中,最初建设IT系统的时刻是一个分隔点。
在此之前,数据零散分布在邮箱、发票、单据、APP等各种地方。
零散的数据分布
企业规模达到一定程度时则必须要建设IT系统,此时,数据开始在各种系统(ERP、CRM、MES等)中积累。
IT系统中的数据分布
数据价值随着其体量不断的累积也在一直增加。
获取其中的知识,能够帮助企业发现问题与机遇并进行正确的决策,以达到赢得市场之目的。
数据分析则是实现以上目标的重要手段之一。
数据分析体系的建设往往是在初次进行信息化建设后某个时间开始。
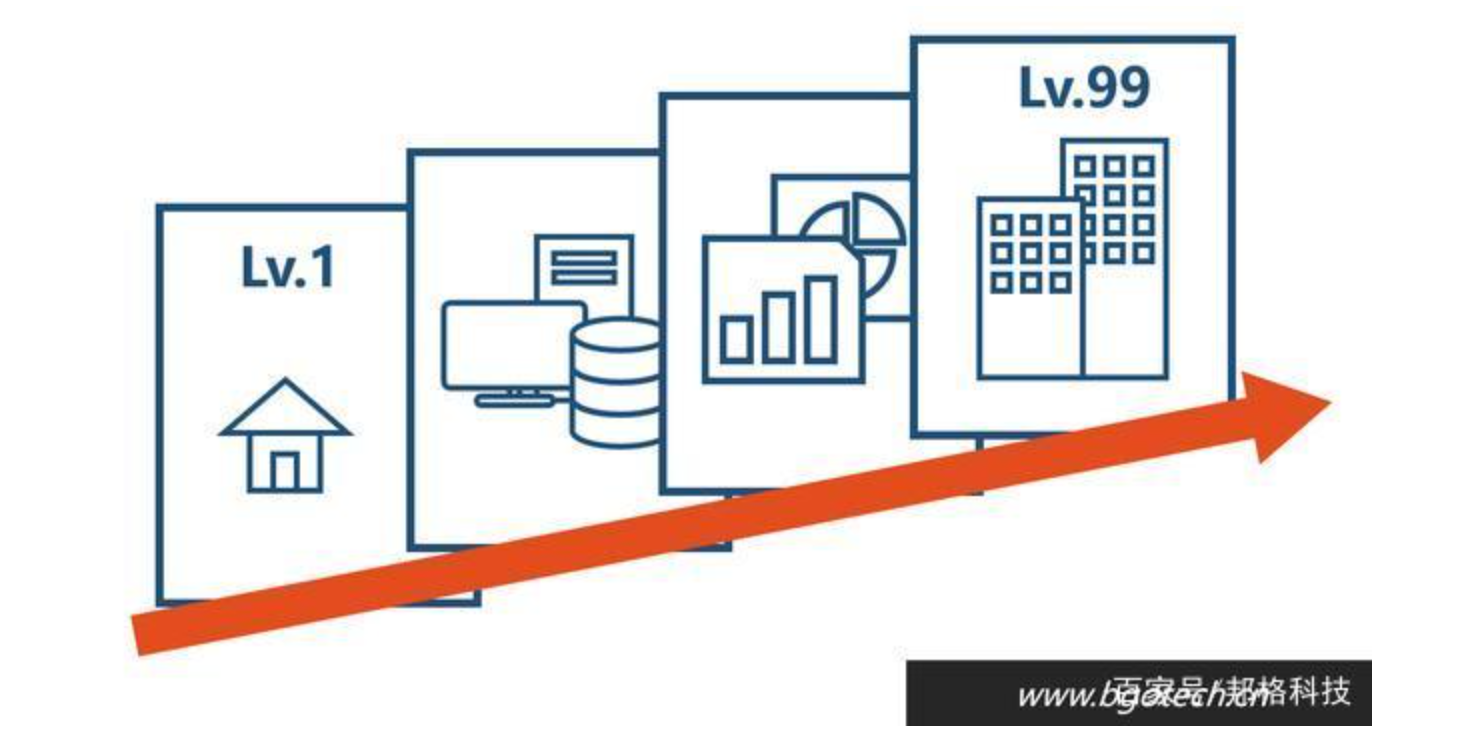
信息化之后数据分析体系的建立
数据分析体系与其他业务类系统有着显著的不同。
业务类系统主要供基层人员使用,进行一线业务操作,通常被称为OLTP(On-Line Transaction Processing,联机事务处理)。
数据分析的目标则是探索并挖掘数据价值,作为企业高层进行决策的参考,通常被称为OLAP(On-Line Analytical Processing,联机分析处理)。
从功能角度来看,OLTP负责基本业务的正常运转,而业务数据积累时所产生的价值信息则被OLAP不断呈现,企业高层通过参考这些信息会不断调整经营方针,也会促进基础业务的不断优化,这是OLTP与OLAP最根本的区别(其他OLTP与OLAP的差别各位可以自行网上搜索,这里不再啰嗦)。
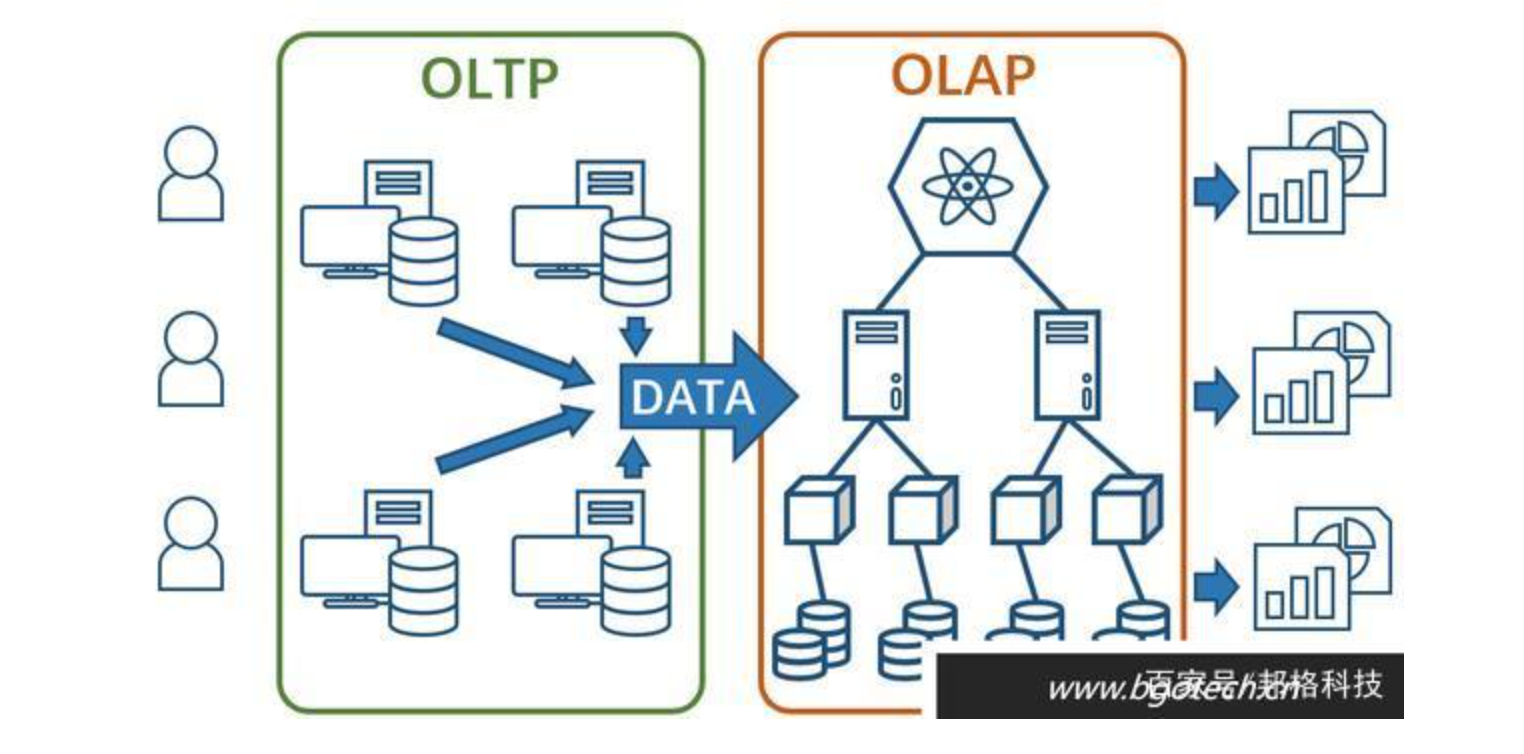
OLTP与OLAP
OLAP不应该对OLTP产生任何影响,(理想情况下)OLTP应该完全感觉不到OLAP的存在。
OLAP核心概念
基本概念
1) 维
维(Dimension):人们观察事物的视角,如时间、地理位置、年龄和性别等,是单一角度概念。
维的层次(Lever of Dimension):表示维度概念基础上进一步的细分,如时间可以细分为年、季度、月三个层次。
维成员(Member of Dimension):表示维不可再细分的原子取值,如时间维的成员可以是2019年1月10日。
度量(Measure):表示在这个维成员上的取值。
2)操作
下探(Drill down):维度是有层次的,下探表示进入维度的下一层,将汇总数据拆分到下一层所在细节数据信息,如下图从第二季度下探到看4、5、6月的明细数据。
上钻(Drill up): 下探的反向操作,回到更高汇聚层的汇总数据。
切片(Slice):切片可以理解成把立体按某一个维度进行切分,就可以看两维数据,如图中按电子产品切分,看到的是时间和地理位置关系的二维数据。
切块(Dice):相对于切片是按一个点切分,切块就是按一个范围(区间)来做切分。
旋转(Pivot):维的行列位置交换,换一个视角分析数据。
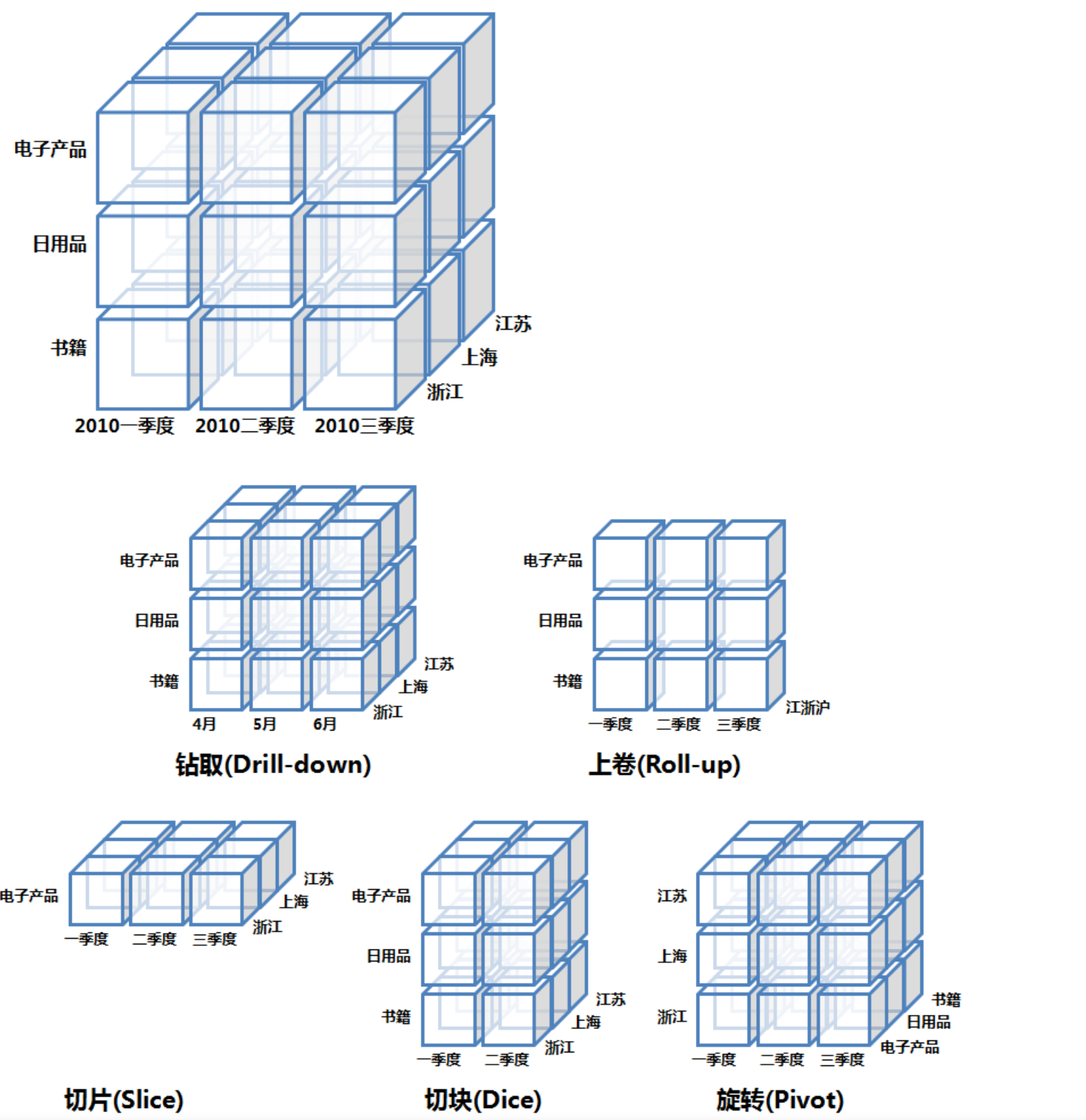
OLAP分类
OLAP按存储器的数据存储格式分为ROLAP、MOLAP和HOLAP。
MOLAP(Multi-dimensional OLAP)
以多维数组(Multi-dimensional Array)存储模型的OLAP,是OLAP发源最初的形态,某些方面也等同于OLAP。它的特点是数据需要预计算(pre-computaion),然后把预计算之后的结果(cube)存在多维数组里。
优点:
cube包含所有维度的聚合结果,所以查询速度非常快。
计算结果数据占用的磁盘空间相对关系型数据库更小
缺点:
空间和时间开销大。update cube的时间跟计算维度(degree)相关,随着维度增加计算时间大幅增加,此外预计算还会造成数据库占用急剧膨胀。
查询灵活度比较低。需要提前设计维度模型,查询分析的内容仅限于这些指定维度,增加维度需要重新计算。
ROLAP(Relational OLAP)
基于关系模型存放数据,一般要求事实表(fact table)和维度表(dimensition table)按一定关系设计,它不需要预计算,使用标准SQL就可以根据需要即时查询不同维度数据。
优点
扩展性强,适用于维度数量多的模型,MOLAP对于维度多的模型预计算慢,空间占用大。
更适合处理non-aggregate事实,例如文本描述
基于row数据更容易做权限管理
缺点
因为是即时计算,查询响应时间一般比预计算的MOLAP长。
HOLAP
业界还没有一致的定义,它是MOLAP和ROLAP类型的混合运用,细节的数据以ROLAP的形式存放,更加方便灵活,而高度聚合的数据以MOLAP的形式展现,更适合于高效的分析处理。公司使用HOLAP的目的是根据不同场景来利用不同OLAP的特性。
OLAP业界产品
MOLAP 产品有 Cognos Powerplay, Oracle Database OLAP Option, MicroStrategy, Microsoft Analysis Services, Essbase, TM1, Jedox ,icCube和kylin等。
ROLAP产品有Vertica、Amazon Redshift、Google Dremel、Hulu Nesto、Presto、Druid、Impala、Greenplum、HAWQ和Doris等。
OLAP场景的关键特征
绝大多数是读请求
数据以相当大的批次(> 1000行)更新,而不是单行更新;或者根本没有更新。
已添加到数据库的数据不能修改。
对于读取,从数据库中提取相当多的行,但只提取列的一小部分。
宽表,即每个表包含着大量的列
查询相对较少(通常每台服务器每秒查询数百次或更少)
对于简单查询,允许延迟大约50毫秒
列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
处理单个查询时需要高吞吐量(每台服务器每秒可达数十亿行)
事务不是必须的
对数据一致性要求低
每个查询有一个大表。除了他以外,其他的都很小。
查询结果明显小于源数据。换句话说,数据经过过滤或聚合,因此结果适合于单个服务器的RAM中
很容易可以看出,OLAP场景与其他通常业务场景(例如,OLTP或K/V)有很大的不同, 因此想要使用OLTP或Key-Value数据库去高效的处理分析查询场景,并不是非常完美的适用方案。例如,使用OLAP数据库去处理分析请求通常要优于使用MongoDB或Redis去处理分析请求。
-